I have a list of panda dataframe;
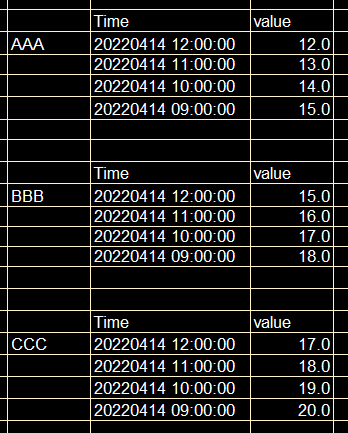
I would like to convert it into a panda dataframe that looks like this;
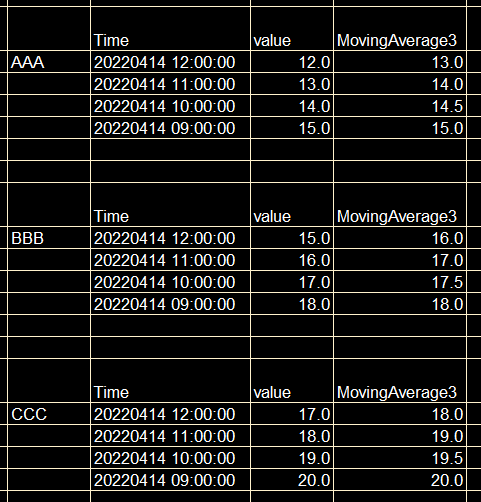
I tried something like panda_series.rolling(window=3).mean(). However, the problem is that the moving average is calculated starting from the last row. What I want is to have the moving average to be calculated starting from the first row.
CodePudding user response:
You can compute the rolling on the reversed Series, and set the min_periods to 1:
df['MA3'] = df['value'][::-1].rolling(window=3, min_periods=1).mean()
Output:
value MA3
0 12 13.0
1 13 14.0
2 14 14.5
3 15 15.0
Note that it is not necessary to reverse the output if you assign it back as a column due to the fact that pandas performs index alignement before inserting the data.
If you're working with an isolated Series, however, you will need to use:
s = df['value'][::-1].rolling(window=3, min_periods=1).mean()[::-1]
# or
# s2 = s1[::-1].rolling(window=3, min_periods=1).mean()[::-1]
CodePudding user response:
I would like to build on the answer by @mozway. Credit goes to him.
To get the right order in the panda series as required in the question, here's the code.
df['MA3'] = df['value'][::-1].rolling(window=3, min_periods=1).mean()
df['MA3'] = df['MA3'][::-1]