I have the script below I typed in Pycharm for my Streamlit Data app:
import pandas as pd
import plotly.express as px
import streamlit as st
st.set_page_config(page_title='Matching Application Number',
layout='wide')
df = pd.read_csv('Analysis_1.csv')
st.sidebar.header("Filter Data:")
MeetingFileType = st.sidebar.multiselect(
"Select File Type:",
options=df['MEETING_FILE_TYPE'].unique(),
default=df['MEETING_FILE_TYPE'].unique()
)
df_selection = df.query(
'MEETING_FILE_TYPE == @MeetingFileType'
)
st.dataframe(df_selection)
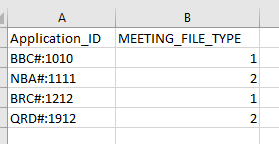
The output of this on streamlit is:
Application_ID MEETING_FILE_TYPE
BBC#:1010 1
NBA#:1111 2
BRC#:1212 1
SAC#:1412 4
QRD#:1912 2
BBA#:1092 4
How can I return matching Application_ID results just for 1&2 like below:
Filter Data: Application_ID MEETING_FILE_TYPE
select type: BBC#:1010 1
1 2 NBA#:1111 2
BRC#:1212 1
QRD#:1912 2
Then, how can I download the data results above from Streamlit into a csv file?, Thank you.
CodePudding user response:
I think you can use csv module to export your output as csv file
import csv
with open('filename.csv') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(df_selection)
CodePudding user response:
Have a look on the code comments.
Code
...
st.dataframe(df_selection)
# Show download button for the selected frame.
# Ref.: https://docs.streamlit.io/library/api-reference/widgets/st.download_button
csv = df_selection.to_csv(index=False).encode('utf-8')
st.download_button(
label="Download data as CSV",
data=csv,
file_name='selected_df.csv',
mime='text/csv',
)
Streamlit output
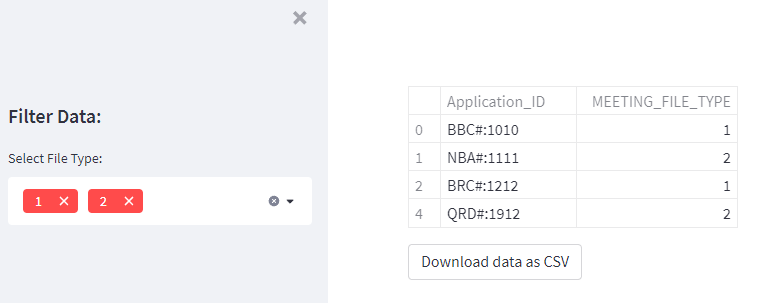
Downloaded csv file selected_df.csv when viewed from excel.