I've been struggling with the following issue that sounds very easy in fact but can't seem to figure it out and I'm sure it's something very obvious in the stacktrace but I'm just being dumb.
I simply have a pandas dataframe looking like this:
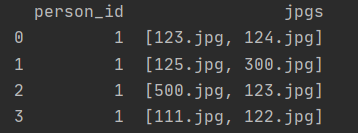
And want to drop the rows that contain, in the jpgs cell value (list), the value "123.jpg". So normally I would get the final dataframe with only rows of index 1 and 3.
However I've tried a lot of methods and none of them works.
For example:
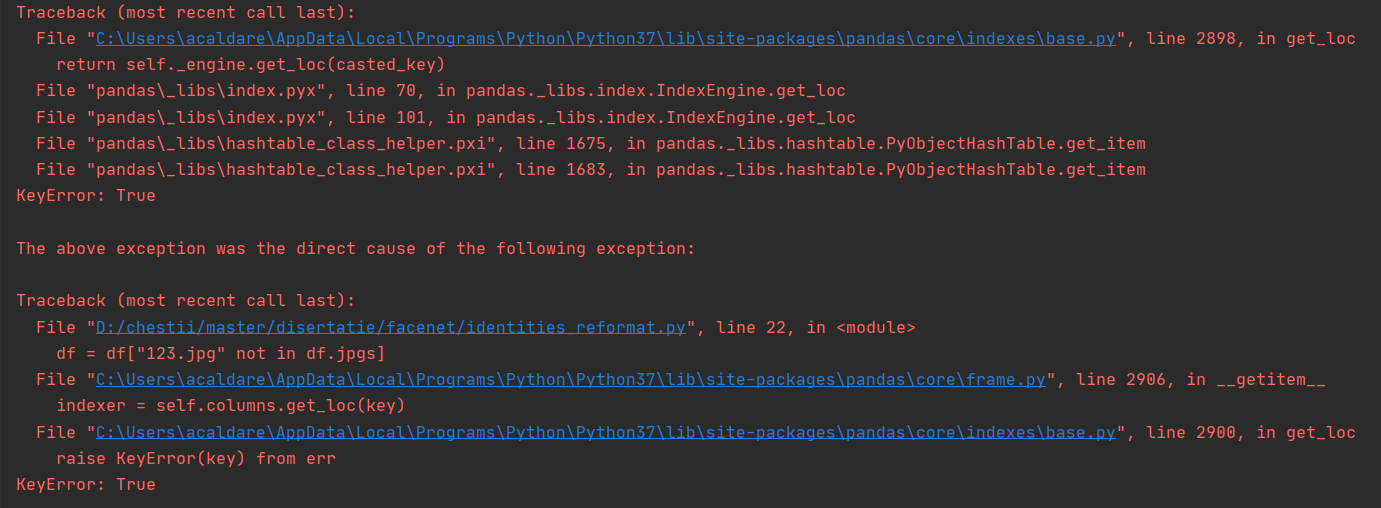
df = df["123.jpg" not in df.jpgs]
or
df = df[df.jpgs.tolist().count("123.jpg") == 0]
give error KeyError: True:
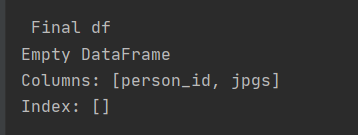
df = df[df['jpgs'].str.contains('123.jpg') == False]
Returns an empty dataframe:
df = df[df.jpgs.count("123.jpg") == 0]
And
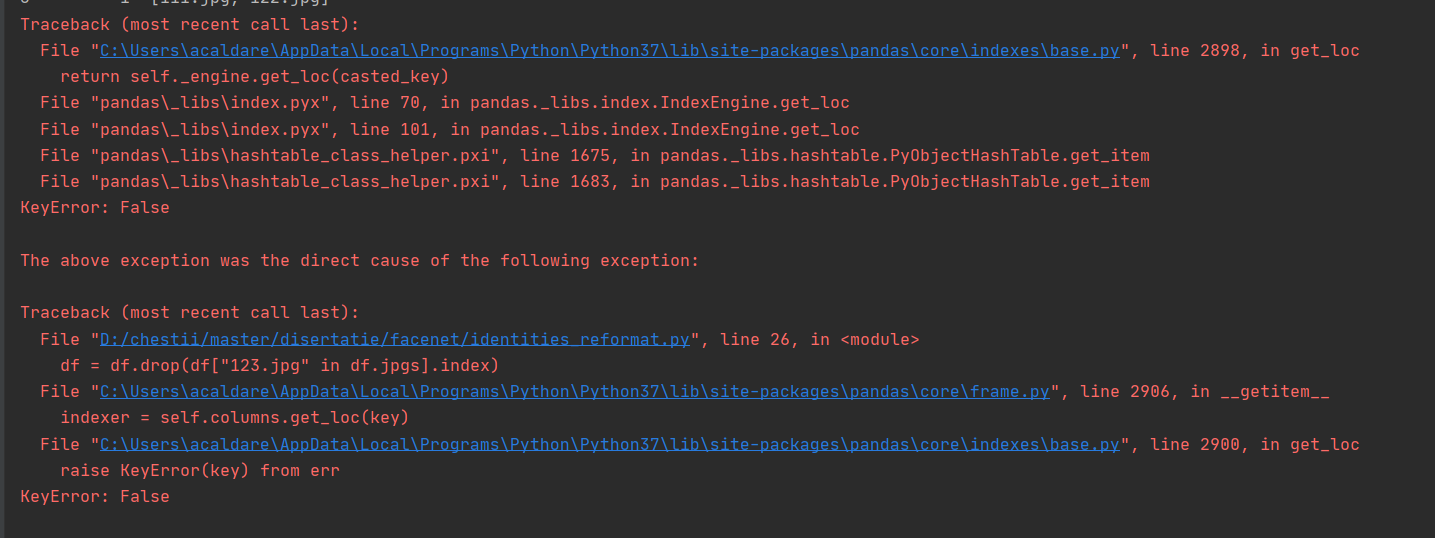
df = df.drop(df["123.jpg" in df.jpgs].index)
Gives KeyError: False:
This is my entire code if needed, and I would really appreciate if someone would help me with an answer to what I'm doing wrong :( . Thanks!!
import pandas as pd
df = pd.DataFrame(columns=["person_id", "jpgs"])
id = 1
pair1 = ["123.jpg", "124.jpg"]
pair2 = ["125.jpg", "300.jpg"]
pair3 = ["500.jpg", "123.jpg"]
pair4 = ["111.jpg", "122.jpg"]
row1 = {'person_id': id, 'jpgs': pair1}
row2 = {'person_id': id, 'jpgs': pair2}
row3 = {'person_id': id, 'jpgs': pair3}
row4 = {'person_id': id, 'jpgs': pair4}
df = df.append(row1, ignore_index=True)
df = df.append(row2, ignore_index=True)
df = df.append(row3, ignore_index=True)
df = df.append(row4, ignore_index=True)
print(df)
#df = df["123.jpg" not in df.jpgs]
#df = df[df['jpgs'].str.contains('123.jpg') == False]
#df = df[df.jpgs.tolist().count("123.jpg") == 0]
df = df.drop(df["123.jpg" in df.jpgs].index)
print("\n Final df")
print(df)
CodePudding user response:
Since you filter on a list column, apply lambda would probably be the easiest:
df.loc[df.jpgs.apply(lambda x: "123.jpg" not in x)]
Quick comments on your attempts:
In
df = df.drop(df["123.jpg" in df.jpgs].index)you are checking whether the exact value "123.jpg" is contained in the column ("123.jpg" in df.jpgs) rather than in any of the lists, which is not what you want.In
df = df[df['jpgs'].str.contains('123.jpg') == False]goes in the right direction, but you are missing theregex=Falsekeyword, as shown in Ibrahim's answer.df[df.jpgs.count("123.jpg") == 0]is also not applicable here, sincecountreturns the total number of non-NaN values in the Series.
CodePudding user response:
For str.contains one this is how it is done
df[df.jpgs.str.contains("123.jpg", regex=False)]
CodePudding user response:
You can try this:
mask = df.jpgs.apply(lambda x: '123.jpg' not in x)
df = df[mask]