I am attempting to use the python urllib.request library to download .pdb (protein data bank) files with the full predicted molecular structure of a given protein from the alphafold website. In this example, I am attempting to download a protein with a uniprot ID of Q9BY15. The entry 
And the manually downloaded file has the following naming format;
Here is the block of code I am using (in its simplest form)
import os
import urllib
import urllib.request
url = 'https://alphafold.ebi.ac.uk/entry/'
prot = 'Q9BY15'
alphaname = 'AF-' prot '-F1-model_v2.pdb'
urllib.request.urlretrieve(url prot, alphaname)
And here is the file that I get when I run the code;
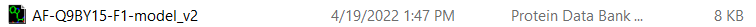
As you can see, the file is far smaller than the actual size of the real file (despite having the exact same name), and is effectively empty when viewing it through protein identification programs. How would I rewrite this code to pull the actual file?
CodePudding user response:
I'm not sure if this will solve your problem but the correct url for downloading the pdb file of Q9BY15 is https://alphafold.ebi.ac.uk/files/AF-Q9BY15-F1-model_v2.pdb
Try replacing /entry/ in the link with /files/.