I have a .txt that goes like this:
USA
Arizona - New Mexico
Interstate 40
Interstate 10
South Dakota - Minneapolis
Interstate 90
South Carolina - Washington
Arizona - California
Interstate 40
Interstate 10
Interstate 8
ANOTHER COUNTRY
State A - State B
Highway 1
Highway 2
Highway 3
...
...
I want to create a DataFrame and a CSV in pandas, where the first column contains the States, and the second column the Highway.
States HW_Number
Arizona - New Mexico Interstate 40
Arizona - New Mexico Interstate 10
South Dakota - Minneapolis Interstate 90
Arizona - California Interstate 40
Arizona - California Interstate 10
Arizona - California Interstate 9
State A - State B Highway 1
State A - State B Highway 2
State A - State B Highway 3
How can I manage to do that? Not all the states have the same amount of Highways, and can have 0 Highways, and those that have 0, I do not want to be integrated in the DataFrame.
A column with the Country could be integrated as well.
Thank you
CodePudding user response:
As I said, a pretty easy file to parse:
import pandas as pd
rows = []
state = None
for line in open('x.txt'):
if line[0] == ' ':
continue
line = line.strip()
if not line:
continue
if '-' in line:
state = line
else:
rows.append( (state,line) )
df = pd.DataFrame(rows, columns=['state','road'])
print(df)
Output:
----------
state road
0 Arizona - New Mexico Interstate 40
1 Arizona - New Mexico Interstate 10
2 South Dakota - Minneapolis Interstate 90
3 Arizona - California Interstate 40
4 Arizona - California Interstate 10
5 Arizona - California Interstate 8
6 State A - State B Highway 1
7 State A - State B Highway 2
8 State A - State B Highway 3
CodePudding user response:
You can iterate through the rows and use characteristics of your structured data to create lists. These lists can be used to make a dataframe or series.
- read the lines from the file into a list (f.readlines())
- remove empty rows
- keep track of current state (doesn't end with a number)
- append the states and highways to lists
- use lists to make a dataframe or series
import pandas as pd
import io
f = io.StringIO(
"""
USA
Arizona - New Mexico
Interstate 40
Interstate 10
South Dakota - Minneapolis
Interstate 90
South Carolina - Washington
Arizona - California
Interstate 40
Interstate 10
Interstate 8
ANOTHER COUNTRY
State A - State B
Highway 1
Highway 2
Highway 3
"""
)
lines = f.readlines()
states = []
hw_numbers = []
current_state = None
for line in lines:
line = line.strip() #removes \n
if line == '': #remove empty rows
continue
elif line[-1].isdigit() == False: #if not a digit, then it's a state
current_state = line
else: #if it is a digit, then it's a highway
states.append(current_state)
hw_numbers.append(line)
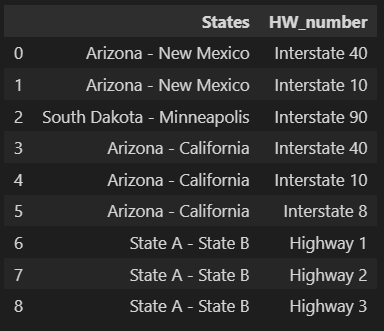
pd.DataFrame({
'States':states,
'HW_number':hw_numbers
})