I have a great looking geom_tile plot, but I need a way to highlight specific rows or label specific rows based on a binary value.
Here is a small subset of data in wide format and resulting output:
df <- structure(list(bin_level = c(0,1), sequence = c("L19088.1", "chr1_43580199_43586187"), X236 = c("G", "."), X237 = c("G", "."), X238 = c("A", "a"),
X239 = c("T", "C"), X240 = c("A", "c"), X241 = c("G", "G"
)), class = "data.frame", row.names = 1:2)
> df
bin_level sequence X236 X237 X238 X239 X240 X241
1 0 L19088.1 G G A T A G
2 1 chr1_43580199_43586187 . . a C c G
The actual dataset is much larger, with 1045 observations of 3096 variables.
My goal is to plot this massive dataset as a heatmap with colors for each different nucleotide and be able to differentiate between rows with bin_levels of 0 and 1.
The following code makes a great plot, but doesn't include the bin_level differences I need to see. I would like to highlight the entire row if the bin_level is 1, but I haven't been able to find anything on how to do such a thing. I am already using nucleotides for the aes fill variable, so I need something else. The best option I've come up with so far is to color the row labels. I used info from 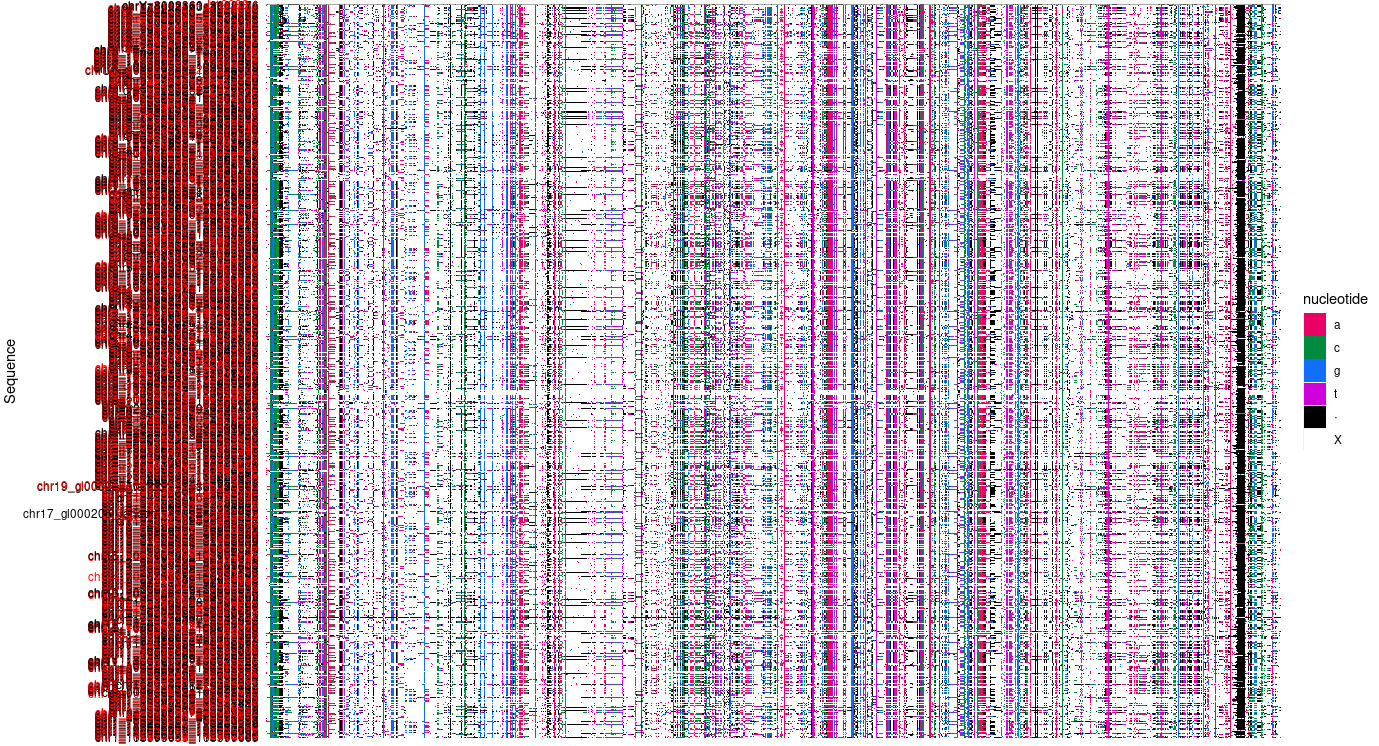
CodePudding user response:
While passing a vector of colors to element_text() is a quick option in some cases IMHO in more general cases it is error prone and requires to keep an eye on the way you ordered your data. Instead I would suggest to have a look at the ggtext package which introduces the theme element element_markdown and allows for styling text using some HTML, CSS and markdown.
Moreover, besides the issue already pointed out by @I_O another issue is that you wrangle the data manipulation steps together with the plotting code in one pipeline. As a consequence while you arrange your data by bin_level you use the original unmanipulated, unarranged dataset df which by the way is still in wide format for the color assignment. That's why personally I would always recommend to split the data wrangling and the plotting except for very simple cases.
Finally, while your arranged your data by bin_level what really matters is the order of sequence, i.e. you have to set the order of sequence after arranging for which I use forecast::fct_inorder.
Note: To make your example more realistic I duplicated your dataset to add two more rows.
library(tidyr)
library(dplyr)
library(ggplot2)
df_long <- df %>%
pivot_longer(-c("sequence", "bin_level"),
names_to = "position",
values_to = "nucleotide"
) %>%
arrange(bin_level) %>%
mutate(
sequence = if_else(bin_level == 1, paste0("<span style='color: red'>", sequence, "</span>"), sequence),
sequence = forcats::fct_inorder(sequence))
ggplot(df_long)
geom_tile(aes(x = position, y = sequence, fill = nucleotide),
height = 1
)
scale_fill_manual(values = c(
"a" = "#ea0064", "c" = "#008a3f", "g" = "#116eff",
"t" = "#cf00dc", "\U00B7" = "#000000", "X" = "#ffffff"
))
labs(x = "x-axis-title", y = "Sequence")
theme(
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank(),
axis.text.y = ggtext::element_markdown()
)

DATA
df <- structure(list(
bin_level = c(0, 1), sequence = c("L19088.1", "chr1_43580199_43586187"), X236 = c("G", "."), X237 = c("G", "."), X238 = c("A", "a"),
X239 = c("T", "C"), X240 = c("A", "c"), X241 = c("G", "G")
), class = "data.frame", row.names = 1:2)
df1 <- structure(list(
bin_level = c(0, 1), sequence = c("L19088.2", "chr1_43580199_43586187.2"), X236 = c("G", "."), X237 = c("G", "."), X238 = c("A", "a"),
X239 = c("T", "C"), X240 = c("A", "c"), X241 = c("G", "G")
), class = "data.frame", row.names = 1:2)
df <- dplyr::bind_rows(df, df1)
CodePudding user response:
While you arrange the data by bin level before feeding it into ggplot, the plot's vertical arrangement follows the y-value (which is: sequence). You could create a combination of bin_level and sequence to arrange and plot the data by:
df %>%
...
## reformat bin_level to a three-digit character, so that
## 002 properly precedes 011 (otherwise 11 would come before 2)
mutate(dummy = paste(sprintf('.0f', bin_level),
Sequence, sep = '_')) %>%
arrange(dummy) %>%
...
## ggplot instructions:
ggplot() ...
geom_tile(aes(y = dummy, ...))
## remove the bin_level prefix ('00x_') for labelling:
scale_y_discrete(labels = gsub('.*_', '', df$dummy))
...
theme(axis.text.y = element_text(
## note: df$bin_level NOT levels(df$bin_level)
colour = ifelse(df$bin_level == 1, "red", "black"))
)
mind that using element_text to colour labels might not function in the future:
Vectorized input to
element_text()is not officially supported. Results may be unexpected or may change in future versions of ggplot2. (console warning)