I have data on the amount of minutes that a machine is active. From this data I get the following distribution plot with minutes on the x axis and the count on the y axis:
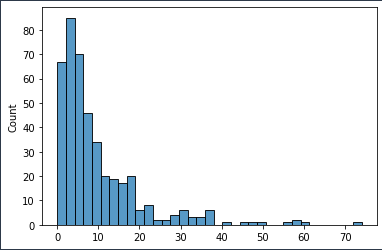
Now I want to create a simulation where the time the machine is active is randomly drawn from this distribution, only I have no idea how to do this. Instinctually I would say that I need to use random.expovariate(), however I have no idea what value I would use as lambda.
Anyone have any ideas?
The data I have is:
randomlist = ([ 0., 1., 11., 2., 4., 6., 5., 5., 2., 7., 8., 4., 4.,
4., 4., 4., 4., 7., 4., 4., 18., 14., 13., 4., 1., 10.,
6., 5., 4., 1., 2., 1., 6., 4., 6., 17., 6., 2., 4.,
7., 17., 19., 18., 4., 9., 4., 7., 4., 14., 12., 4., 3.,
2., 8., 8., 7., 4., 7., 6., 3., 6., 6., 13., 2., 16.,
6., 4., 6., 11., 10., 6., 10., 9., 4., 9., 4., 9., 1.,
5., 4., 10., 8., 8., 7., 3., 20., 12., 5., 1., 11., 8.,
5., 5., 9., 1., 5., 2., 12., 3., 6., 3., 4., 8., 1.,
3., 1., 14., 5., 4., 20., 4., 11., 3., 9., 14., 37., 4.,
19., 31., 20., 11., 28., 8., 16., 5., 15., 1., 3., 11., 30.,
4., 8., 4., 28., 2., 1., 22., 1., 74., 7., 22., 5., 7.,
5., 3., 2., 7., 8., 19., 37., 8., 4., 1., 12., 3., 18.,
11., 7., 30., 4., 13., 6., 5., 4., 1., 4., 4., 6., 9.,
45., 1., 1., 5., 4., 2., 5., 1., 3., 2., 12., 35., 33.,
3., 20., 4., 10., 4., 2., 4., 4., 4., 2., 6., 8., 7.,
11., 3., 7., 2., 15., 4., 7., 16., 22., 38., 8., 12., 4.,
5., 2., 6., 18., 2., 6., 60., 3., 16., 10., 59., 4., 4.,
15., 55., 6., 23., 1., 2., 6., 58., 1., 18., 2., 3., 2.,
34., 6., 1., 3., 7., 13., 1., 5., 5., 14., 6., 19., 1.,
37., 6., 11., 50., 6., 5., 29., 17., 9., 8., 17., 8., 9.,
7., 6., 6., 6., 9., 9., 1., 8., 5., 16., 7., 9., 12.,
5., 3., 15., 1., 3., 2., 18., 6., 15., 24., 34., 3., 3.,
12., 1., 29., 16., 13., 12., 3., 15., 7., 9., 9., 10., 3.,
37., 2., 10., 4., 8., 1., 8., 31., 5., 1., 5., 19., 12.,
41., 5., 6., 2., 3., 2., 4., 8., 5., 14., 9., 6., 6.,
4., 9., 3., 3., 7., 10., 14., 13., 15., 7., 14., 31., 6.,
3., 19., 16., 33., 6., 4., 2., 16., 1., 18., 10., 24., 14.,
7., 2., 1., 2., 6., 2., 2., 14., 8., 3., 5., 37., 6.,
6., 9., 21., 23., 4., 6., 18., 16., 23., 3., 9., 4., 9.,
5., 1., 6., 1., 1., 23., 8., 6., 1., 33., 4., 3., 15.,
5., 9., 27., 17., 7., 4., 9., 47., 7., 6., 4., 30., 4.,
27., 13., 22., 12., 2., 21., 13., 9., 6., 14., 5., 7., 18.,
7., 2., 2., 4., 2., 4., 4., 10., 1., 5., 9.])
CodePudding user response:
random.choices allows you to provide weights
import random
from collections import Counter
randomList = [...]
c = Counter(randomlist)
num_samples = 100
print(random.choices(list(c.keys()), weights=list(c.values()), k=num_samples))
In my example I'm calculating weights from your randomList but you could pre-calculate offline if you don't want to do it in your script.
CodePudding user response:
Well, if you want to use np.random.expovariate() that implies an assumption about your data being exponentially distributed. If you are happy with that, you can use the Scipy library to fit an exponential function and deduce your rate parameter. Good step-by-step instructions can be find eg. here.
Alternatively, as suggested above, just use np.random.choice()