I have two queries:
SELECT
COUNT(warehouseCode) as count,
warehouseCode
FROM 'sparePartEventsTable'
WHERE
sparePartCode = 'SP.0000' AND
sparePartConsumed = 'true'
GROUP BY warehouseCode
ORDER BY count DESC
and
SELECT
COUNT(*) as eventsCount,
DATE(TIMESTAMP_SECONDS(epochSeconds)) as day
FROM 'sparePartEventsTable'
WHERE
sparePartCode = 'SP.0000' AND
sparePartConsumed = 'true'
GROUP BY day
ORDER BY day
As you can see the underlying data is the same, but I'm returning two different aggregations. Is there a way in SQL to avoid hitting the disk twice?
How would you implement this is either BigQuery or Postgres?
In mongodb I would build a cursor on the underlying common data, and then write an aggregation pipeline that spits two results.
EDIT: It seems that UNION ALL could be a first solution, but at least in postgres it scans twice. Sergey in the comment suggested GROUPING SETS, but unfortunately they are not available in BigQuery. An answer in either Postgres or BigQuery dialect will be accepted, extra points if both solutions are posted :)
CodePudding user response:
Consider below (BigQuery) option
with temp as (
select
warehouseCode,
count(*) over(partition by warehouseCode) as `count`,
date(timestamp_seconds(epochSeconds)) as day,
count(*) over(partition by unix_date(date(timestamp_seconds(epochSeconds)))) as eventsCount
from `sparePartEventsTable`
where sparePartCode = 'SP.0000'
and sparePartConsumed = 'true'
)
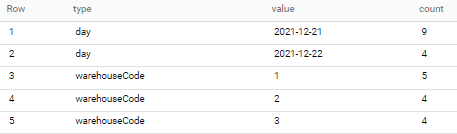
select distinct 'warehouseCode' type, '' || warehouseCode as value, `count` from temp union all
select distinct 'day', string(day), eventsCount from temp
with output like below