How I can sum the previous three-row values and have that value in the current row of a new column in python.
You need to consider the IS_DEFAULT Column Sum.
DEFAULT_3_MONTHS is my new column name.
Input:
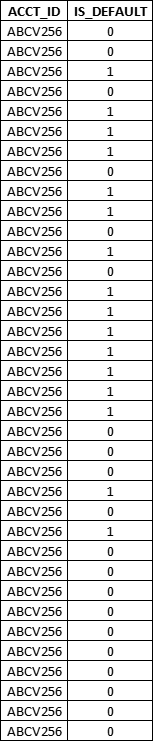 .
.
Expected output:
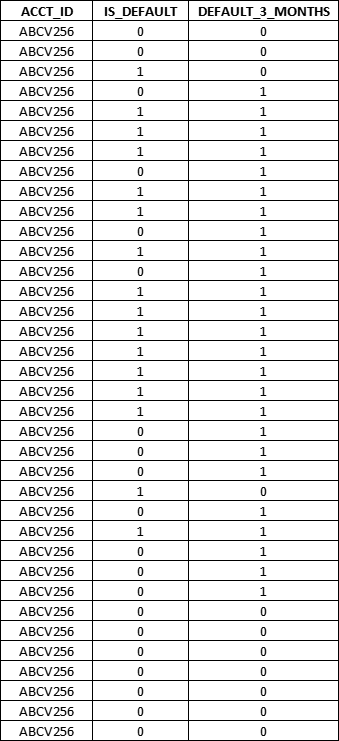
CodePudding user response:
You can use:
df['DEFAULT_3_MONTHS'] = (
df.assign(IS_DEFAULT=df['IS_DEFAULT'].shift(fill_value=0))
.groupby('ACCT_ID').rolling(3, min_periods=0)['IS_DEFAULT']
.max().astype(int).droplevel(0)
)
Output:
>>> df
ACCT_ID IS_DEFAULT DEFAULT_3_MONTHS
0 ABCV256 0 0
1 ABCV256 0 0
2 ABCV256 1 0
3 ABCV256 0 1
4 ABCV256 1 1
5 ABCV256 1 1
6 ABCV256 1 1
7 ABCV256 0 1
8 ABCV256 1 1
9 ABCV256 1 1
10 ABCV256 0 1
11 ABCV256 1 1
12 ABCV256 0 1
13 ABCV256 1 1
14 ABCV256 1 1
15 ABCV256 1 1
16 ABCV256 1 1
17 ABCV256 1 1
18 ABCV256 1 1
19 ABCV256 1 1
20 ABCV256 0 1
21 ABCV256 0 1
22 ABCV256 0 1
23 ABCV256 1 0
24 ABCV256 0 1
25 ABCV256 1 1
26 ABCV256 0 1
27 ABCV256 0 1
28 ABCV256 0 1
29 ABCV256 0 0
30 ABCV256 0 0
31 ABCV256 0 0
32 ABCV256 0 0
33 ABCV256 0 0
34 ABCV256 0 0
35 ABCV256 0 0
CodePudding user response:
If you are using pandas, I think this should work:
df["DEFAULT_3_MONTHS"] = df.IS_DEFAULT.shift().rolling(3, min_periods = 0).max()