I started playing around with Twitter API v2 in Tweepy. I've had some experience with v1 but it looks like it's changed a bit.
I'm trying to search tweets based on my query and later extract some meaningful information. The code is following:
response = client.search_recent_tweets(
"innovation -is:retweet lang:pl",
max_results = 100,
tweet_fields = ['author_id','created_at','text','source','lang','geo'],
user_fields = ['name','username','location','verified'],
expansions = ['geo.place_id', 'author_id'],
place_fields = ['country','country_code']
)
Now, the issue is I'm not really sure how to read the output. I can easily access basic info with tweet object in the following way:
for tweet in response.data:
print(tweet.text)
print(tweet.lang)
etc..
But how do I access other information, such as user_id for tweet object? As this information is in second list of response => response.includes['user']
There are no unique ids (at least I don't see them) to match this info with info from response.data
Below I'm adding an example output of my code. Response consists of iterables for data, includes, errors and meta. The thing is, the iterables don't seem to be always equal in size, meaning that I can't just take data[0] and includes['user'][0] etc.
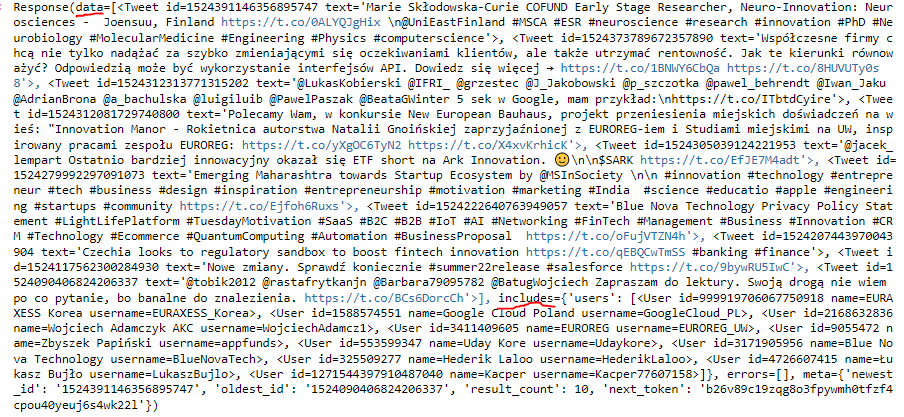
CodePudding user response:
The response of the Twitter API looks like that:
{
"data": [
{
"id": "...",
"author_id": "2244994945",
"geo": {
"place_id": "01a9a39529b27f36"
},
}
],
"includes": {
"users": [
{
"id": "2244994945",
"created_at": "..."
}
],
"places": [
{
"id": "01a9a39529b27f36",
"country": "..."
}
]
}
}
So you should have in each tweet:
- The
author_idfield which is theidof theUserobject in theincludes; - The
geo['place_id']field which is theidof thePlaceobject in theincludes.
CodePudding user response:
Tweepy is a great tool for working with Twitter API: I use it myself as well. Under the hood the method you are using accesses the search recent tweets api As you can see in the Examples section, the API itself definitely provides an author id in the response data. Which means that Tweepy has it saved as well.
What you're actually seeing in the screenshot you've provided is the string representation of the Tweepy objects. This does not mean that the data is not there, however.
Here's a slightly modified version of your code:
import tweepy
client = tweepy.Client("YOUR BEARER TOKEN HERE")
response = client.search_recent_tweets(
"innovation -is:retweet lang:pl",
max_results = 100,
tweet_fields = ['author_id','created_at','text','source','lang','geo'],
user_fields = ['name','username','location','verified'],
expansions = ['geo.place_id', 'author_id'],
place_fields = ['country','country_code']
)
for tweet in response.data:
print(tweet.author_id) # print the author id of the tweet
print(tweet.text) # print the text
print(tweet.data['lang']) # print the language (PL, since we're filtering by it)
print(tweet.data['source']) # what did the user use to publish the tweet?
Hope that helps :)