I am trying to fetch a URL from a webpage, here is how the URL looks in the Inspect section:
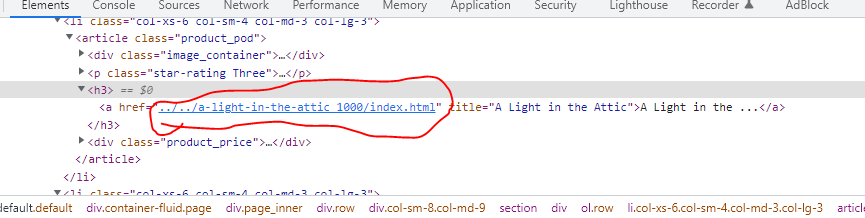
Here is how the URL looks in my python-code:
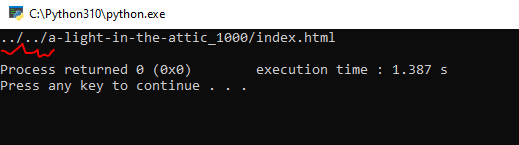
How can I get the actual URL without the ../../ part using BeautifulSoup? Here is my code in case it's needed:
import re
import requests
from bs4 import BeautifulSoup
source = requests.get('https://books.toscrape.com/catalogue/category/books_1/index.html').text
soup = BeautifulSoup(source, 'lxml')
# article = soup.find('article')
# title = article.div.a.img['alt']
# print(title['alt'])
titles, topics,urls,sources = [], [], [],[]
article_productPod = soup.findAll('article', {"class":"product_pod"})
for i in article_productPod:
titles.append(i.div.a.img['alt'])
# print(titles)
for q in article_productPod:
urls.append(q.h3.a['href'])
print(urls[0])
# for z in range(len(urls)):
# source2 = requests.get("https://" urls[z])
CodePudding user response:
Use urllib:
import urllib
Store your target URL in a separate variable :
src_url = r'https://books.toscrape.com/catalogue/category/books_1/index.html'
source = requests.get(src_url).text
Join the website's URL and the relative URL:
for q in article_productPod:
urls.append(urllib.parse.urljoin(src_url, q.h3.a['href']))