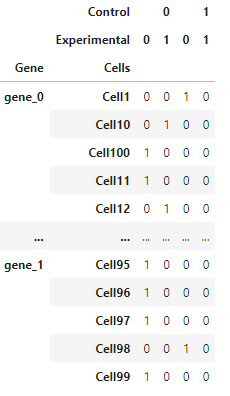
First, for gene G, I want to create a pandas dataframe for control and experimental conditions, where the ratio of 0:1 is 10% and 20%, respectively.
import pandas as pd
n = 5000
df = pd.DataFrame.from_dict(
{"Cells": (f'Cell{x}' for x in range(1, n 1)), "Control": np.random.choice([1,0], p=[0.1, 0.9], size=n), "Experimental": np.random.choice([1,0], p=[0.1 0.1, 0.9-0.1], size=n)},
orient='columns'
)
df = df.set_index("Cells")
Second, I perform cross-tabulation analysis for gene G.
# Contingency table/array
table = pd.crosstab(df.index, [df["Control"], df["Experimental"]])
table
Now, I want to extrapolate the conditions from step 1 and 2 for 1000 genes and then perform cross-tabulation. How?
CodePudding user response:
There are multiple ways to handle it. One of the easiest would be:
- Wrap the simulation procedure in a function and run it for each gene to create a list of genes based results.
- Concat all the gene_based simulations and run the crosstab function to get the contingency tables in a single dataframe.
Something like:
n = 100 # no of records per simulation/ gene
nog = 2 # no of genes
gene_list = ["gene_" str(i) for i in range(0,nog)]
# simulation procedure
def generate_gene_df(gene, n):
df = pd.DataFrame.from_dict(
{"Gene" : gene,
"Cells": (f'Cell{x}' for x in range(1, n 1)),
"Control": np.random.choice([1,0], p=[0.1, 0.9], size=n),
"Experimental": np.random.choice([1,0], p=[0.1 0.1, 0.9-0.1], size=n)},
orient='columns'
)
df = df.set_index(["Gene","Cells"])
return df
# create a list of gene based simulations generated using your procedure
gene_df_list = [generate_gene_df(gene, n) for gene in gene_list]
single_genes_df = pd.concat(gene_df_list)
single_genes_df = single_genes_df.reset_index()
table = pd.crosstab([single_genes_df["Gene"], single_genes_df["Cells"]],
[single_genes_df["Control"], single_genes_df["Experimental"]])
table