Good day
I have the following data set that basically serves as a key to another data set.
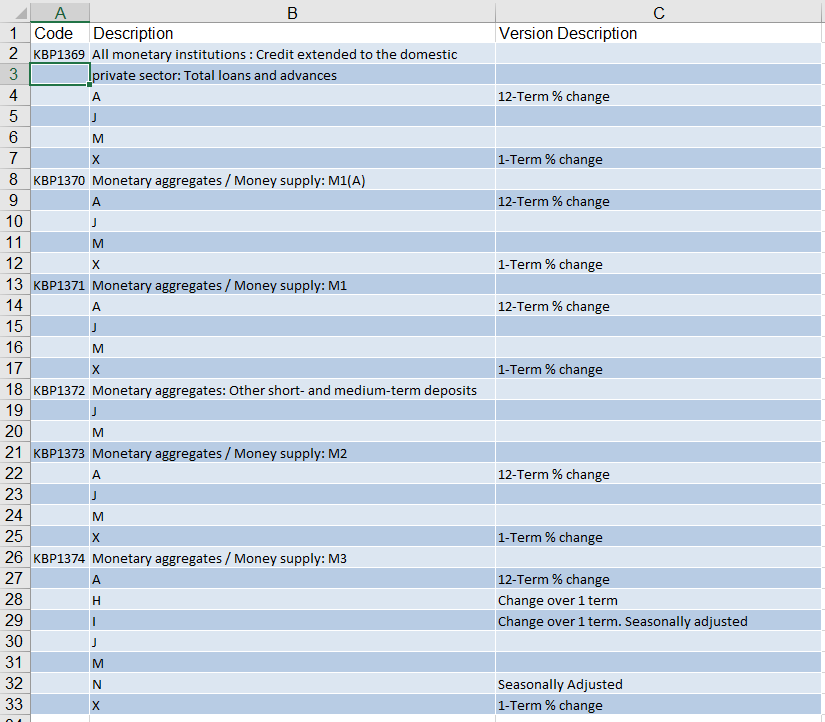
A short example section in code form
Code = c("KBP1369"," "," "," ","KBP1370"," "," ", " "," ")
Description = c("All monetary institutions Credit extended to the domestic ","private sector Total loans and advances","A","J","Monetary aggregates / Money supply: M1(A)", "A","J","M","X")
Data=data.frame(Code,Description)
I need to somehow create a column that contains the code and the letter under the description column.
So basically I need something along these lines.
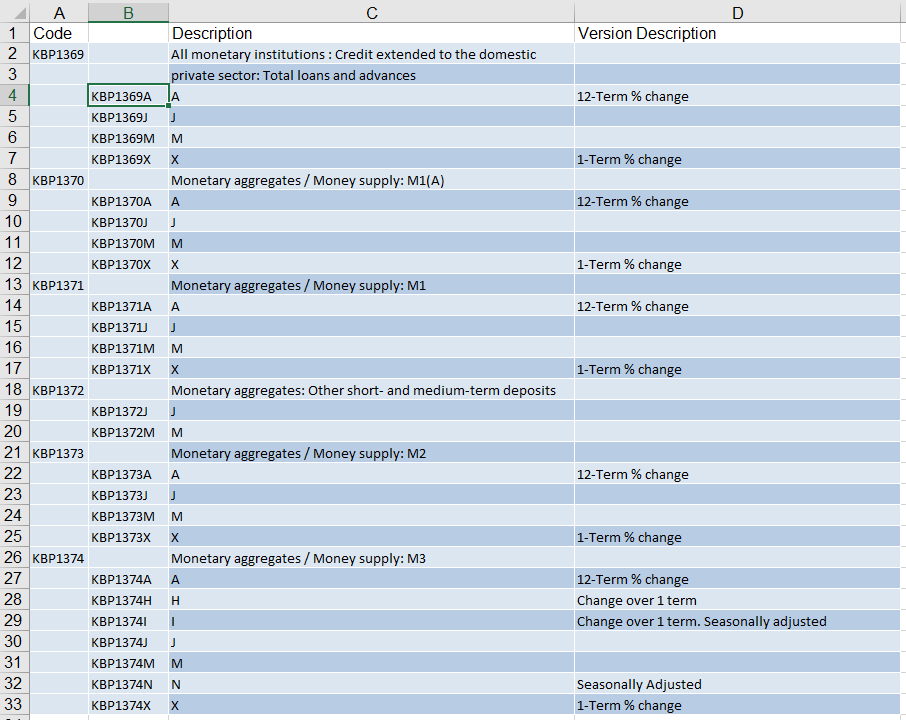
I just don't know how since in some cases the wordy description runs over 1 line and other times only over one. On top of that, the number of letter rows differ two, like for example KBP1369 has 4 letter descriptions but KBP1372 only has 2. How on earth do I do this??
CodePudding user response:
An idea is to convert empty strings to NA, fill and paste with the single character strings, i.e.
library(dplyr)
Data %>%
mutate(Code1 = replace(Code, Code == ' ', NA)) %>%
tidyr::fill(Code1) %>%
mutate(Code1 = ifelse(nchar(Description) == 1, paste0(Code1, Description), ''))
Code Description Code1
1 KBP1369 All monetary institutions Credit extended to the domestic
2 private sector Total loans and advances
3 A KBP1369A
4 J KBP1369J
5 KBP1370 Monetary aggregates / Money supply: M1(A)
6 A KBP1370A
7 J KBP1370J
8 M KBP1370M
9 X KBP1370X
To include the new results in the original Code column then simply modify that in mutate, i.e.
Data %>%
mutate(Code1 = replace(Code, Code == ' ', NA)) %>%
tidyr::fill(Code1) %>%
mutate(Code = ifelse(nchar(Description) == 1, paste0(Code1, Description), Code))