I am working with time-use data and want to calculate the duration of a started measurement at each time step (per column) and select the longest duration for each measurement. The measurement are numbered from 1 to 27. The length is weighted with 1 (e.g increment is set to 1). I am not sure how to handle if a measurement is fragmented and has multiple durations times.
Data format:
Desired output (example for the measurement number 1):
Time Measurement Duration
04:00 1 1
04:10 1 1
04:20 1 2
04:20 1 2
04:20 1 2
Longest duration
Time Measurement Duration
04:20 1 2
Sample data:
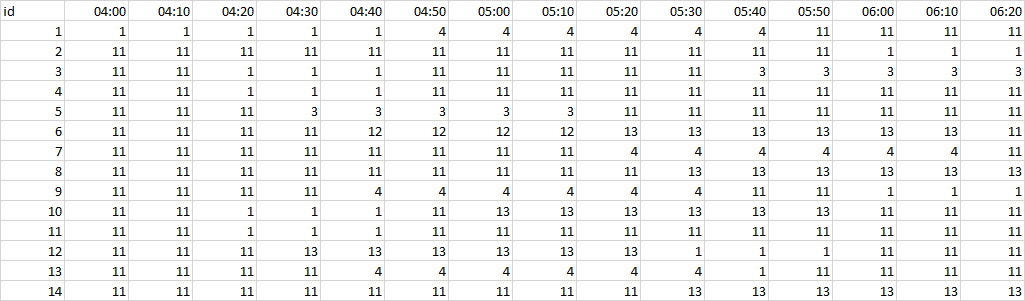
df<-structure(list(id = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14), `04:00` = c(1, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11,
11, 11, 11), `04:10` = c(1, 11, 11, 11, 11, 11, 11, 11, 11, 11,
11, 11, 11, 11), `04:20` = c(1, 11, 1, 1, 11, 11, 11, 11, 11,
1, 1, 11, 11, 11), `04:30` = c(1, 11, 1, 1, 3, 11, 11, 11, 11,
1, 1, 13, 11, 11), `04:40` = c(1, 11, 1, 1, 3, 12, 11, 11, 4,
1, 1, 13, 4, 11), `04:50` = c(4, 11, 11, 11, 3, 12, 11, 11, 4,
11, 11, 13, 4, 11), `05:00` = c(4, 11, 11, 11, 3, 12, 11, 11,
4, 13, 11, 13, 4, 11), `05:10` = c(4, 11, 11, 11, 3, 12, 11,
11, 4, 13, 11, 13, 4, 11), `05:20` = c(4, 11, 11, 11, 11, 13,
4, 11, 4, 13, 11, 13, 4, 11), `05:30` = c(4, 11, 11, 11, 11,
13, 4, 13, 4, 13, 11, 1, 4, 13), `05:40` = c(4, 11, 3, 11, 11,
13, 4, 13, 11, 13, 11, 1, 1, 13), `05:50` = c(11, 11, 3, 11,
11, 13, 4, 13, 11, 13, 11, 1, 11, 13), `06:00` = c(11, 1, 3,
11, 11, 13, 4, 13, 1, 11, 11, 11, 11, 13), `06:10` = c(11, 1,
3, 11, 11, 13, 4, 13, 1, 11, 11, 11, 11, 13), `06:20` = c(11,
1, 3, 11, 11, 11, 11, 13, 1, 11, 11, 11, 11, 13)), row.names = c(NA,
-14L), spec = structure(list(cols = list(id = structure(list(), class = c("collector_double",
"collector")), `04:00` = structure(list(), class = c("collector_double",
"collector")), `04:10` = structure(list(), class = c("collector_double",
"collector")), `04:20` = structure(list(), class = c("collector_double",
"collector")), `04:30` = structure(list(), class = c("collector_double",
"collector")), `04:40` = structure(list(), class = c("collector_double",
"collector")), `04:50` = structure(list(), class = c("collector_double",
"collector")), `05:00` = structure(list(), class = c("collector_double",
"collector")), `05:10` = structure(list(), class = c("collector_double",
"collector")), `05:20` = structure(list(), class = c("collector_double",
"collector")), `05:30` = structure(list(), class = c("collector_double",
"collector")), `05:40` = structure(list(), class = c("collector_double",
"collector")), `05:50` = structure(list(), class = c("collector_double",
"collector")), `06:00` = structure(list(), class = c("collector_double",
"collector")), `06:10` = structure(list(), class = c("collector_double",
"collector")), `06:20` = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), delim = ","), class = "col_spec"), class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"))
CodePudding user response:
Here's a function, mainly using rle, that will get you the desired output for a specific measurement:
f <- function(n){
l <- lapply(df[-1], \(x) with(rle(x), lengths[values == n]))
enframe(l, name = "Time", value = "Duration") %>%
unnest("Duration") %>%
mutate(Measurement = n, .before = "Duration")
}
output
> f(1)
# A tibble: 20 × 3
Time Measurement Duration
<chr> <dbl> <int>
1 04:00 1 1
2 04:10 1 1
3 04:20 1 1
4 04:20 1 2
5 04:20 1 2
6 04:30 1 1
7 04:30 1 2
8 04:30 1 2
9 04:40 1 1
10 04:40 1 2
11 04:40 1 2
12 05:30 1 1
13 05:40 1 2
14 05:50 1 1
15 06:00 1 1
16 06:00 1 1
17 06:10 1 1
18 06:10 1 1
19 06:20 1 1
20 06:20 1 1
Get the maximum with slice_max:
f(1) %>%
slice_max(Duration, n = 1, with_ties = F)
# A tibble: 1 × 3
Time Measurement Duration
<chr> <dbl> <int>
1 04:20 1 2
CodePudding user response:
library(tidyverse)
library(lubridate)
df %>%
pivot_longer(-id, names_to = "timepoint", values_to = "Measurement") %>%
arrange(id, Measurement) %>%
type_convert() %>%
group_by(id) %>%
# Duration to first time point for each id
mutate(Duration = timepoint - min(timepoint)) %>%
# get the longest duration
filter(Duration == max(Duration))
#>
#> ── Column specification ────────────────────────────────────────────────────────
#> cols(
#> timepoint = col_time(format = "")
#> )
#> # A tibble: 14 × 4
#> # Groups: id [14]
#> id timepoint Measurement Duration
#> <dbl> <time> <dbl> <drtn>
#> 1 1 06:20 11 8400 secs
#> 2 2 06:20 1 8400 secs
#> 3 3 06:20 3 8400 secs
#> 4 4 06:20 11 8400 secs
#> 5 5 06:20 11 8400 secs
#> 6 6 06:20 11 8400 secs
#> 7 7 06:20 11 8400 secs
#> 8 8 06:20 13 8400 secs
#> 9 9 06:20 1 8400 secs
#> 10 10 06:20 11 8400 secs
#> 11 11 06:20 11 8400 secs
#> 12 12 06:20 11 8400 secs
#> 13 13 06:20 11 8400 secs
#> 14 14 06:20 13 8400 secs
Created on 2022-05-16 by the reprex package (v2.0.0)