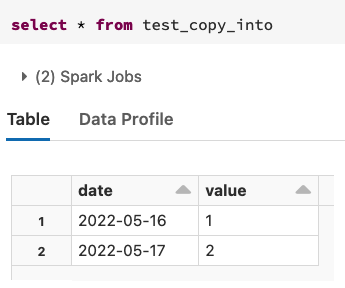
I have one landing S3 buckets, which will receive each day some data, partitioned by date :
s3:/my_bucket/date=2020-01-01/my_data.txt
s3:/my_bucket/date=2020-01-02/my_data.txt
s3:/my_bucket/date=2020-01-03/my_data.txt
I did create a first test Delta table partitioned on date column, using SQL, then I did :
COPY INTO delta.my_table FROM (SELECT date, value FROM 's3:/my_bucket/') FILEFORMAT = TEXT
Everything is working well, then ... Today I had a new partitionFolder on that bucket :
s3:/my_bucket/date=2020-01-04/my_data.txt
I have NO idea how to "copy into" only that new folders, and keep date partitioning value. Basically, I can't re-use same sql statement to copy, because it will copy previous files (other date, which are already inside delta table).
I did try by specify directly folder path like that :
COPY INTO delta.my_table FROM (SELECT date, value FROM 's3:/my_bucket/date=2020-01-04') FILEFORMAT = TEXT
but Delta/Spark is not able to get "date column", because it's read directly files and not subfolder which contains date column information.
SQL AnalysisException: cannot resolve 'date' given input columns: [value];
I wanted to add some "Pattern" matching on subfolder like
COPY INTO delta.my_table FROM (SELECT date, value FROM 's3:/my_bucket/') FILEFORMAT = TEXT
PÄTTERN = 'date=2020-01-04/*'
but same errors, spark is not able to understand that this folder is a new partition.
My question is quite simple, is it possible to use 'COPY INTO' from a incremental partitioned s3 buckets (like my example).
PS : My Delta table is an external table, which link to an other s3 bucket.
s3:/my_bucket/ is supposed to be only landing zone and should be immutable.
CodePudding user response:
COPY INTO is idempotent operation - it won't load the data from the files that were already processed, at least until you explicitly will ask it with COPY_OPTIONS(force=true) (see 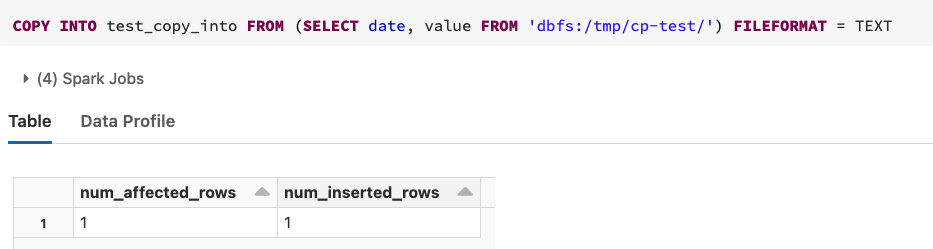
- Check that you have data loaded:
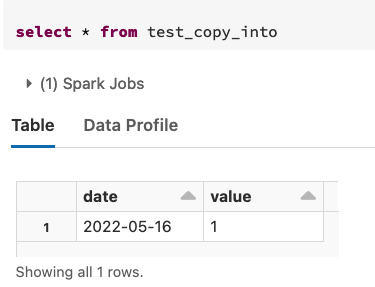
- Create a file with content
2, upload it to the filedbfs:/tmp/cp-test/date=2022-05-17/1.txt, and import it as well - you see that we imported only one row, although we have old files there:
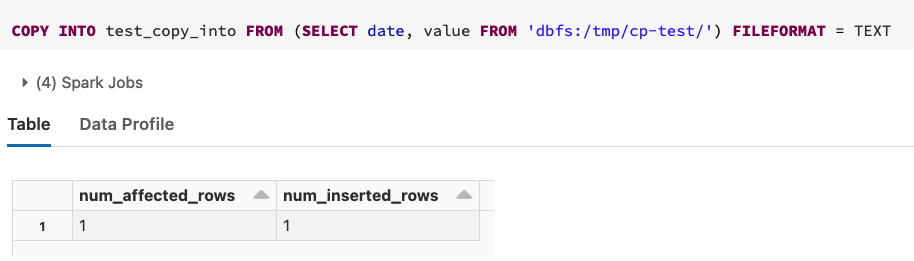
- And if we look into data, we see that we have only 2 rows as it's supposed: