I have seven dataframes with hundreds of rows each(don't ask) that I need to combine on a column. I know how to use the inner join functionality. In Pandas. What I need help with is that there are instances where these seven data frames have columns with the same names. In those instances, I would like to combine the data therein and delimit with a semicolon.
For example, if Row 1 in DF1 through DF7 have the same identifier, I would like Col1 in each dataframe (given they have the same name) to be combined to read:
dfdata1; dfdata2; ...;dfdata7
In cases where a column name is unique, I'd like it to appear in the final combined dataframe.
I've included a simple example
import pandas as pd
data1 = pd.DataFrame([['Banana', 'Sally', 'CA'], ['Apple', 'Gretta', 'MN'], ['Orange', 'Samantha', 'NV']],
columns=['Product', 'Cashier', 'State'])
data2 = pd.DataFrame([['Shirt','', 'CA'], ['Shoe', 'Trish', 'MN'], ['Socks', 'Paula', 'NM', 'Hourly']],
This yields two dataframes:
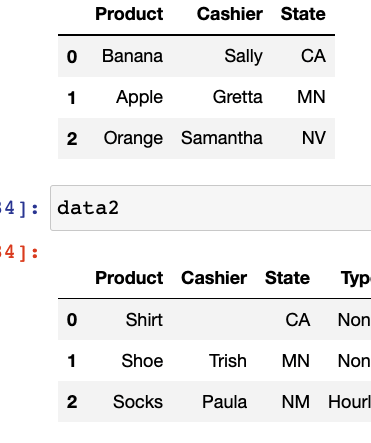
If we were to use an outer merge on state:
pd.merge(data1,data2,on='State',how='outer')
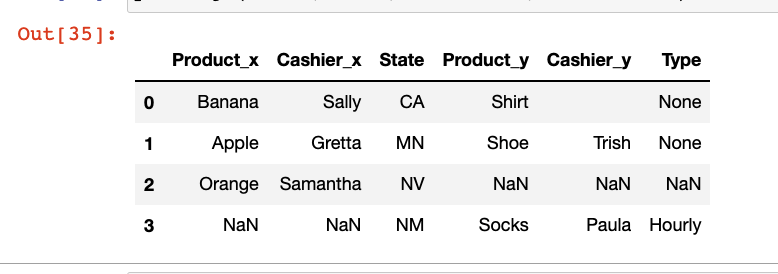
What I want is something more like this:
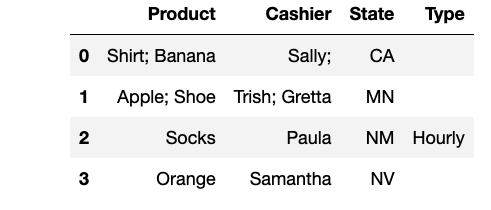
Is this doable in pandas or will I have to merge the first two, combine the columns with the same names, then move on to combine THAT with the third one etc. I'm trying to be as efficient as possible.
CodePudding user response:
Instead of merging, concatenate
# concatenate and groupby to join the strings
df = pd.concat([data1, data2]).groupby('State', as_index=False).agg(lambda x: '; '.join(el for el in x if pd.notna(el)))
print(df)
State Product Cashier Type
0 CA Banana; Shirt Sally;
1 MN Apple; Shoe Gretta; Trish
2 NM Socks Paula Hourly
3 NV Orange Samantha