I have a DataFrame with multiple columns and rows. The rows are student names with marks and the columns are marking criteria. I want to save the first row (column names) along with each row in seperate files with the name of the student as the name file.
Example of my data:
| Marking_Rubric | Requirements and Delivery\nWeight 45.00% | Coding Standards\nWeight 10.00% | Documentation\nWeight 25.00% | Runtime - Effectiveness\nWeight 10.00% | Efficiency\nWeight 10.00% | Total | Comments |
|---|---|---|---|---|---|---|---|
| John Doe | 54 | 50 | 90 | 45 | 50 | 31 | Limited documentation |
| Jane Doe | 23 | 12 | 87 | 10 | 34 | 98 | No comments |
Desired output:
| Marking_Rubric | Requirements and Delivery | Coding Standards | Documentation | Runtime - Effectiveness | Efficiency | Total | Comments |
|---|---|---|---|---|---|---|---|
| John Doe | 54 | 50 | 90 | 45 | 50 | 31 | Limited documentation |
| Marking_Rubric | Requirements and Delivery | Coding Standards | Documentation | Runtime - Effectiveness | Efficiency | Total | Comments |
|---|---|---|---|---|---|---|---|
| Jane Doe | 23 | 12 | 87 | 10 | 34 | 98 | No comments |
CodePudding user response:
Just note that you have to have a unique name to save a file. Otherwise files with the same name will overwrite each other.
# `````````````````````````````````````````````````````````````````````````
### create dummy data
column1_list = ['John Doe','John Doe','Not John Doe','special ß ß %&^ character name', 'no special character name again']
column2_list = [53,23,100,0,10]
column3_list = [50,12,200,0,10]
df = pd.DataFrame({'Marking_Rubric': column1_list,
'Requirements and Delivery': column2_list,
'Coding Standards': column3_list})
# `````````````````````````````````````````````````````````````````````````
### create unique identifier that will be used as name of file, otherwise
### you will overwrite files with the same name
df['row_number'] = df.index
df['Marking_Rubric_Rowed'] = df.Marking_Rubric " " df.row_number.astype(str)
df
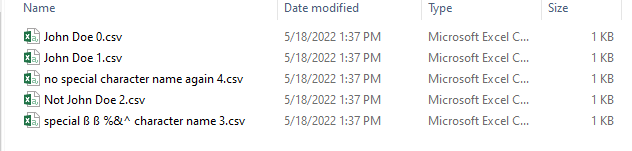
Output 1
# `````````````````````````````````````````````````````````````````````````
### create a loop the length of your dataframe and save each row as a csv
for x in range(0,len(df)):
### try to save file
try:
### get your current row of data first then selecting name of your file ,
### if you want another name just change column
df[x:x 1].to_csv(df[x:x 1].Marking_Rubric_Rowed.iloc[0] '.csv', #### selecting name for your file here
index=False)
### catch and print out exception if something went wrong
except Exception as e:
print(e)
### continue your loop, you could also put "break" to break your loop
continue
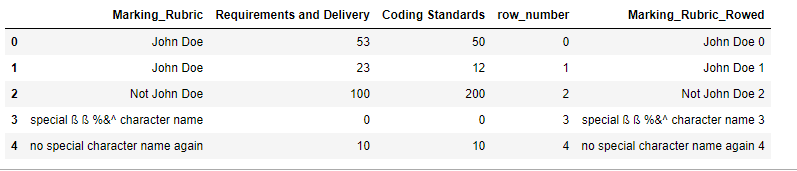
Output 2