Given this DF:
df = pd.DataFrame({'Col1':['A','A','A','B','B','B','B']
, 'Col2':['i', 'j', 'k', 'l', 'm', 'n', 'o']
, 'Col3':['Apple', 'Peach', 'Apricot', 'Dog', 'Cat', 'Mouse', 'Horse']
,})
df
And then using this code:
df1 = df.groupby('Col1').agg({'Col2':'count', 'Col3': lambda x: x.iloc[2]})
df1
I got this result:
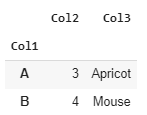
What I would like now:
Being able to make the lambda function 'Col3': lambda x: x.iloc[0] to print('Not enough data') when dealing with error for example if I change "x.iloc[0]" to "x.iloc[3]" which raised an error because there's not enough data in "Col1['A'] compared to "Col1['B']".
!! Don't want to use 'last' because this is a simplified and shortened DF for purpose !!
CodePudding user response:
You can use nth that will give you a NaN if the value is missing. Unfortunately, nth is not handled by agg so you need to compute it separately and join:
g = df.groupby('Col1')
df1 = g.agg({'Col2':'count'}).join(g['Col3'].nth(3))
output:
Col2 Col3
Col1
A 3 NaN
B 4 Horse
CodePudding user response:
You can try with a slice object which will return empty Series if none value.
df1 = df.groupby('Col1').agg({'Col2':'count',
'Col3': lambda x: x.iloc[3:4] if len(x.iloc[3:4]) else pd.NA})
print(df1)
Col2 Col3
Col1
A 3 <NA>
B 4 Horse
You can save typing with named expression if your Python version is greater than 3.8
df1 = df.groupby('Col1').agg({'Col2':'count',
'Col3': lambda x: v if len(v := x.iloc[3:4]) else pd.NA})