The following code checks for partial matches and adds a comment for if a partial match does or does not exist (it works great!):
import pandas as pd
import numpy as np
x = {'Non-Suffix' : ['1234569', '1234554', '1234567', '1234568','Hello'], 'Suffix' : ['1234567:C', '1234568:VXCF', 'ABCDEFU', '1234569-01', '1234554-01:XC']}
x = pd.DataFrame({k: pd.Series(v) for k, v in x.items()})
x['"Non-Suffix" Partial Match in "Suffix"?'] = x['Non-Suffix'].apply(lambda v: x['Suffix'].str.contains(v).any()).replace({True: '--'}).replace({False: 'Add to Suffix'}).replace({np.nan: '--'})
x['"Suffix" Partial Match in "Non-Suffix"?'] = x['Suffix'].str.contains('|'.join(x['Non-Suffix'])).replace({True: '--'}).replace({False: 'Remove from Suffix'}).replace({np.nan: '--'})
x
#code breaks if anything is added to 'Suffix' column

However, in practice, columns of the same length will not always be compared. In fact, most of the time, columns of varying lengths will be compared. If I add a value to the Non-Suffix column ('StackOverflowIsAwesome'), the code breaks:
x = {'Non-Suffix' : ['1234569', '1234554', '1234567', '1234568','Hello'], 'Suffix' : ['1234567:C', '1234568:VXCF', 'ABCDEFU', '1234569-01', '1234554-01:XC','HelloAdele']}
x = pd.DataFrame({k: pd.Series(v) for k, v in x.items()})
x['"Non-Suffix" Partial Match in "Suffix"?'] = x['Non-Suffix'].apply(lambda v: x['Suffix'].str.contains(v).any()).replace({True: '--'}).replace({False: 'Add to Suffix'}).replace({np.nan: '--'})
x['"Suffix" Partial Match in "Non-Suffix"?'] = x['Suffix'].str.contains('|'.join(x['Non-Suffix'])).replace({True: '--'}).replace({False: 'Remove from Suffix'}).replace({np.nan: '--'})
x
#code breaks if anything is added to 'Suffix' column
Here is the error that confirms the differing lengths between columns:
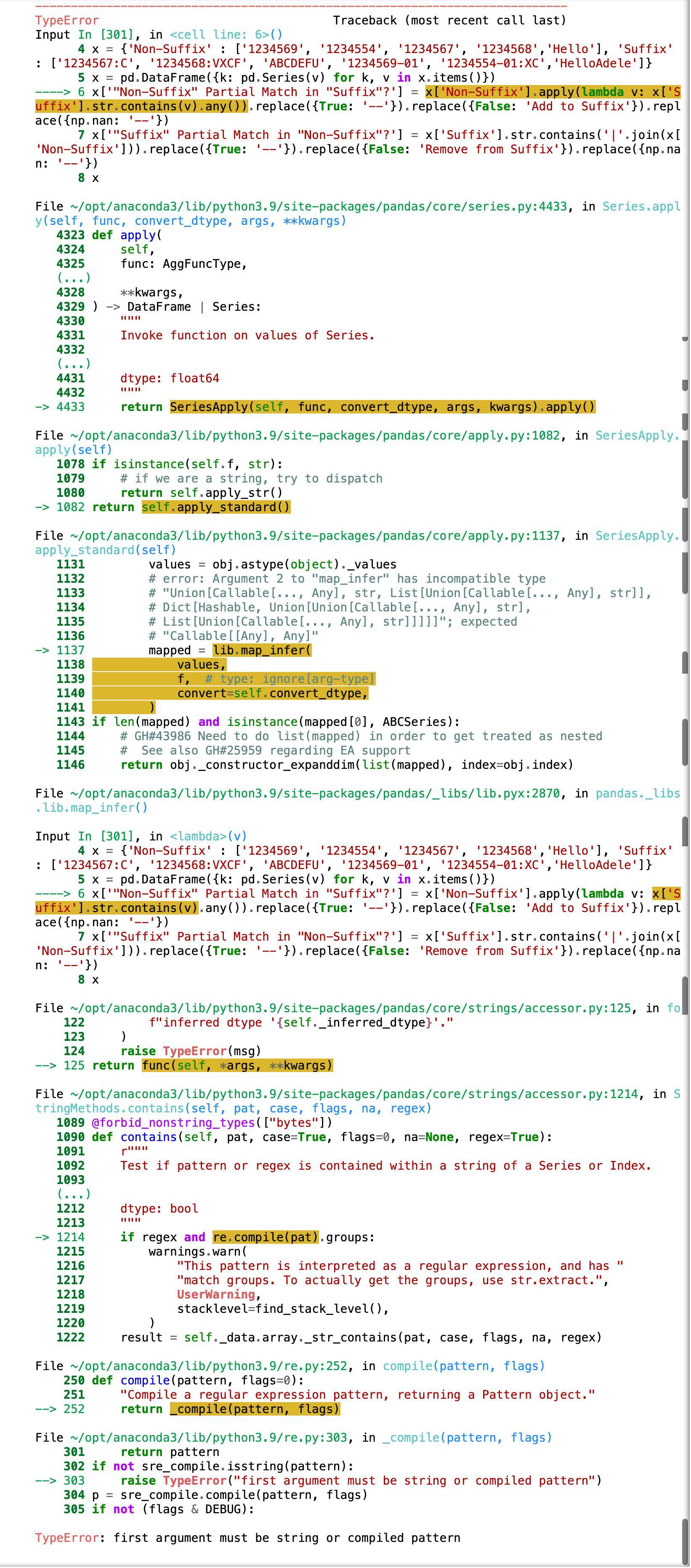
I'd like to be able to add something (like the 'HelloAdele' in the Suffix column and not have the code break. Note: I can add values to the Non-Suffix column, but not the Suffix column. Any tips on how to overcome this is greatly appreciated!
CodePudding user response:
I think something like this should work:
import pandas as pd
import numpy as np
x = {'Non-Suffix' : ['1234569', '1234554', '1234567', '1234568','Hello'], 'Suffix' : ['1234567:C', '1234568:VXCF', 'ABCDEFU', '1234569-01', '1234554-01:XC','HelloAdele']}
x = pd.DataFrame({k: pd.Series(v) for k, v in x.items()})
print()
print(x)
x['"Non-Suffix" Partial Match in "Suffix"?'] = x['Non-Suffix'].apply(
lambda v: False if v is np.nan else x['Suffix'].str.contains(v).any()).replace({True: '--'}).replace({False: 'Add to Suffix'}).replace({np.nan: '--'})
x['"Suffix" Partial Match in "Non-Suffix"?'] = x['Suffix'].str.contains('|'.join(
y for y in x['Non-Suffix'] if y is not np.nan)).replace({True: '--'}).replace({False: 'Remove from Suffix'}).replace({np.nan: '--'})
print(x)
We basically special-case NaN in Non-Suffix and set the result to False, and in Suffix we skip NaN when building the pattern to match.
Input:
Non-Suffix Suffix
0 1234569 1234567:C
1 1234554 1234568:VXCF
2 1234567 ABCDEFU
3 1234568 1234569-01
4 Hello 1234554-01:XC
5 NaN HelloAdele
Output:
Non-Suffix Suffix "Non-Suffix" Partial Match in "Suffix"? "Suffix" Partial Match in "Non-Suffix"?
0 1234569 1234567:C -- --
1 1234554 1234568:VXCF -- --
2 1234567 ABCDEFU -- Remove from Suffix
3 1234568 1234569-01 -- --
4 Hello 1234554-01:XC -- --
5 NaN HelloAdele Add to Suffix --