I have students names, scores in different subjects, subjects names. I want to add a column to the data frame, which contains the subject in which each student had the highest score. Here is the data:
Input data would be:
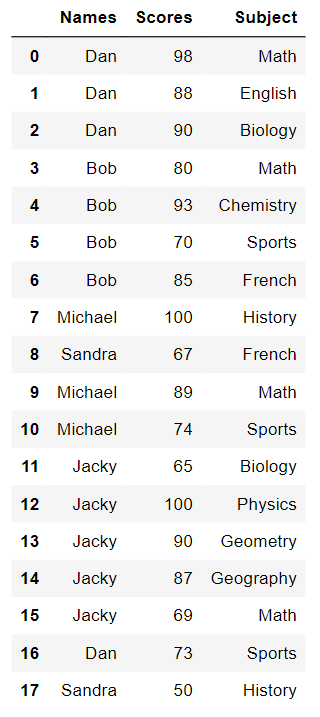
Output data (the result data frame) would be :
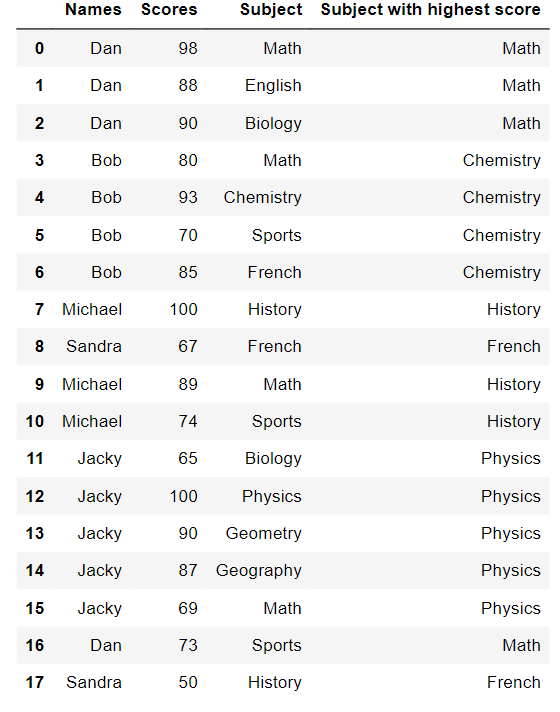
My try at this (didn't work obviously):
Data['Subject with highest score'] = Data.groupby(['Names','Subject'])[['Scores']].transform(lambda x: x.max())
CodePudding user response:
Sort the values by Scores, then group the dataframe by Names and transform the column Subject with last
df['S(max)'] = df.sort_values('Scores').groupby('Names')['Subject'].transform('last')
Alternatively, we can group the dataframe by Names then transform Scores with idxmax to broadcast the indices corresponding to row having max Score, then use those indices to get the corresponding rows from Subject column
df['S(max)'] = df.loc[df.groupby('Names')['Scores'].transform('idxmax'), 'Subject'].tolist()
Names Scores Subject S(max)
0 Dan 98 Math Math
1 Dan 88 English Math
2 Dan 90 Biology Math
3 Bob 80 Math Chemistry
4 Bob 93 Chemistry Chemistry
5 Bob 70 Sports Chemistry
6 Bob 85 French Chemistry
7 Michael 100 History History
8 Sandra 67 French French
9 Michael 89 Math History
10 Michael 74 Sports History
11 Jacky 65 Biology Physics
12 Jacky 100 Physics Physics
13 Jacky 90 Geometry Physics
14 Jacky 87 Geography Physics
15 Jacky 69 Math Physics
16 Dan 73 Sports Math
17 Sandra 50 History French