I have a dataframe structured as follows:
import pandas as pd
import pandas as pd
data = {'date': ['2022-05-01 04:34:00', '2022-05-01 06:24:00', '2022-05-01 18:02:00', '2022-05-02 04:45:00'],
'equipA_w1': ['NaN', 'NaN', 'NaN', 'NaN'],
'equipB_w1': ['NaN', 'x', 'NaN', 'NaN'],
'equipB_w2': ['NaN', 'NaN', 'y', 'z'],
'equipB_w3': ['NaN', 'NaN', 'y', 'NaN'],
'equipC_w2': ['NaN', 'x', 'x', 'NaN'],
'equipA_e2': ['NaN', 'NaN', 'NaN', 'z'],
'equipC_e1': ['y', 'NaN', 'NaN', 'NaN']
}
df = pd.DataFrame(data)

I would like to create a new dataframe that would end up like this:
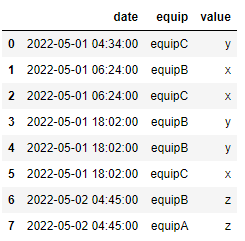
Is there a simple way to do it using pandas?
CodePudding user response:
This will do what your question asks:
df = df.set_index('date').stack().to_frame().reset_index()
df.columns=['date','equip','value']
df = df[df.value != 'NaN'].reset_index(drop=True)
df.equip = df.equip.str.split('_').str[0]
Full test code:
import pandas as pd
data = {'date': ['2022-05-01 04:34:00', '2022-05-01 06:24:00', '2022-05-01 18:02:00', '2022-05-02 04:45:00'],
'equipA_w1': ['NaN', 'NaN', 'NaN', 'NaN'],
'equipB_w1': ['NaN', 'x', 'NaN', 'NaN'],
'equipB_w2': ['NaN', 'NaN', 'y', 'z'],
'equipB_w3': ['NaN', 'NaN', 'y', 'NaN'],
'equipC_w2': ['NaN', 'x', 'x', 'NaN'],
'equipA_e2': ['NaN', 'NaN', 'NaN', 'z'],
'equipC_e1': ['y', 'NaN', 'NaN', 'NaN']
}
df = pd.DataFrame(data)
print(df)
df = df.set_index('date').stack().to_frame().reset_index()
df.columns=['date','equip','value']
df = df[df.value != 'NaN'].reset_index(drop=True)
df.equip = df.equip.str.split('_').str[0]
print(df)
Input:
date equipA_w1 equipB_w1 equipB_w2 equipB_w3 equipC_w2 equipA_e2 equipC_e1
0 2022-05-01 04:34:00 NaN NaN NaN NaN NaN NaN y
1 2022-05-01 06:24:00 NaN x NaN NaN x NaN NaN
2 2022-05-01 18:02:00 NaN NaN y y x NaN NaN
3 2022-05-02 04:45:00 NaN NaN z NaN NaN z NaN
Output:
date equip value
0 2022-05-01 04:34:00 equipC y
1 2022-05-01 06:24:00 equipB x
2 2022-05-01 06:24:00 equipC x
3 2022-05-01 18:02:00 equipB y
4 2022-05-01 18:02:00 equipB y
5 2022-05-01 18:02:00 equipC x
6 2022-05-02 04:45:00 equipB z
7 2022-05-02 04:45:00 equipA z
CodePudding user response:
Another way:
(df.reset_index().melt(['index', 'date'],var_name = 'equip')
.query('value!="NaN"')
.assign(equip = lambda x:x.equip.str.replace('_.*', '', regex = True))
.sort_values('index'))
index date equip value
24 0 2022-05-01 04:34:00 equipC y
5 1 2022-05-01 06:24:00 equipB x
17 1 2022-05-01 06:24:00 equipC x
10 2 2022-05-01 18:02:00 equipB y
14 2 2022-05-01 18:02:00 equipB y
18 2 2022-05-01 18:02:00 equipC x
11 3 2022-05-02 04:45:00 equipB z
23 3 2022-05-02 04:45:00 equipA z
or simply use janitor:
import janitor
(df.pivot_longer('date', names_to = 'equip', names_pattern = '(equip.)', sort_by_appearance = True)
.query('value != "NaN"')
.reset_index(drop =True))
date equip value
0 2022-05-01 04:34:00 equipC y
1 2022-05-01 06:24:00 equipB x
2 2022-05-01 06:24:00 equipC x
3 2022-05-01 18:02:00 equipB y
4 2022-05-01 18:02:00 equipB y
5 2022-05-01 18:02:00 equipC x
6 2022-05-02 04:45:00 equipB z
7 2022-05-02 04:45:00 equipA z
Where the names_pattern is a regular expression capturing what the input of the column should be. in the case, the expressions (equip[A-Z] ) or even ([^_] ) etc will work
CodePudding user response:
here is one way to accomplish it
df2=df.melt( id_vars='date',var_name='equip', value_name='val')
df2['equip'] = df2['equip'].replace(r'_..','', regex=True)
df2.groupby(['date','equip','val']).last().reset_index()
df2.drop(df2[df2['val'] == 'NaN'].index, inplace=True)
df2
date equip val
5 2022-05-01 06:24:00 equipB x
10 2022-05-01 18:02:00 equipB y
11 2022-05-02 04:45:00 equipB z
14 2022-05-01 18:02:00 equipB y
17 2022-05-01 06:24:00 equipC x
18 2022-05-01 18:02:00 equipC x
23 2022-05-02 04:45:00 equipA z
24 2022-05-01 04:34:00 equipC y
CodePudding user response:
#Rename columns and use pd wide_long then dropnas. In this case I use query to leave NaNs out
df =df.rename(columns=dict(zip(df.columns,df.columns.str.replace('(?<=equip)\w ','1', regex=True))))
df1=pd.wide_to_long(df, stubnames='equip', i=['date'], j='age').droplevel(level=1).query("equip.isin(['x','y','z'])",engine='python')
equip
date
2022-05-01 06:24:00 x
2022-05-01 18:02:00 y
2022-05-02 04:45:00 z
2022-05-01 18:02:00 y
2022-05-01 06:24:00 x
2022-05-01 18:02:00 x
2022-05-02 04:45:00 z
2022-05-01 04:34:00 y