I am trying to perform a slice with multiple conditions without success. Here is what my dataframe looks like
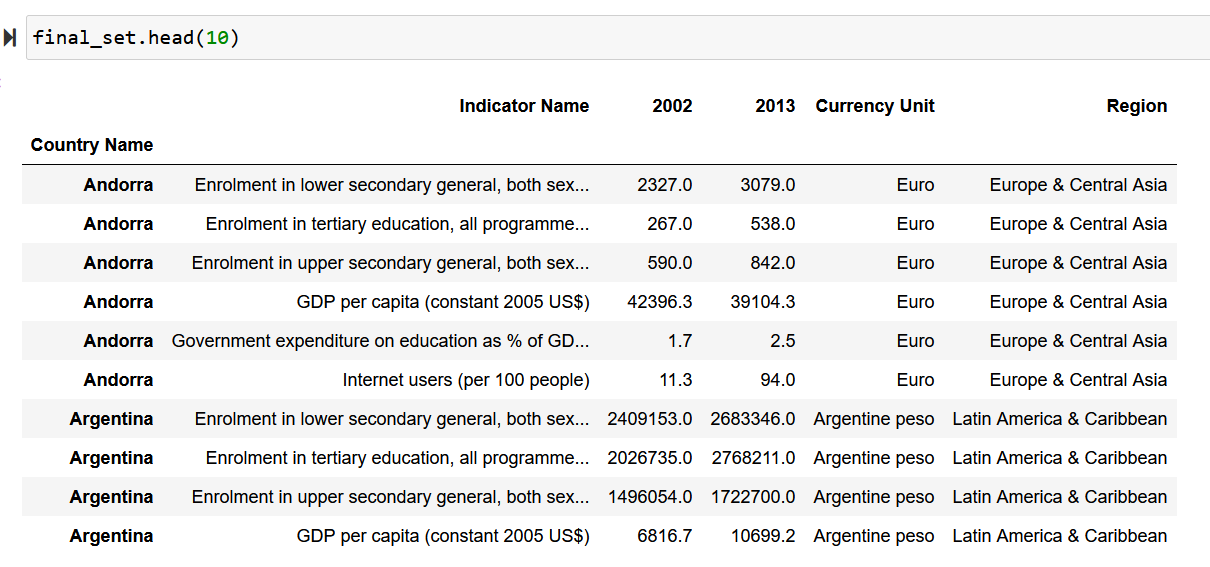
I have many countries, which names are stored as indexes. And for all those countries I have 7 different variables.
My goal is to select all the countries (and therefore all their variables) which 'GDP per capita (constant 2005 US$')' is superior or equal than a previously defined treshold (gdp_min), OR that are named 'China', 'India', or 'Brazil'.
To do so, I have tried many different things but still cannot find a way to do it. Here is my last try, with the error.
gdp_set = final_set[final_set['Indicator Name'] == 'GDP per capita (constant 2005 US$)']['2013'] >= gdp_min | final_set.loc[['China', 'India', 'Brazil']]
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) ~\anaconda3\lib\site-packages\pandas\core\ops\array_ops.py in na_logical_op(x, y, op) 301 # (xint or xbool) and (yint or bool) --> 302 result = op(x, y) 303 except TypeError:
~\anaconda3\lib\site-packages\pandas\core\roperator.py in ror_(left, right) 55 def ror_(left, right): ---> 56 return operator.or_(right, left) 57
TypeError: ufunc 'bitwise_or' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last) ~\anaconda3\lib\site-packages\pandas\core\ops\array_ops.py in na_logical_op(x, y, op) 315 try: --> 316 result = libops.scalar_binop(x, y, op) 317 except (
~\anaconda3\lib\site-packages\pandas_libs\ops.pyx in pandas._libs.ops.scalar_binop()
ValueError: Buffer has wrong number of dimensions (expected 1, got 2)
The above exception was the direct cause of the following exception:
TypeError Traceback (most recent call last) ~\AppData\Local\Temp/ipykernel_16016/3232205269.py in ----> 1 gdp_set = final_set[final_set['Indicator Name'] == 'GDP per capita (constant 2005 US$)']['2013'] >= gdp_min | final_set.loc[['China', 'India', 'Brazil']]
~\anaconda3\lib\site-packages\pandas\core\generic.py in array_ufunc(self, ufunc, method, *inputs, **kwargs) 2030 self, ufunc: np.ufunc, method: str, *inputs: Any, **kwargs: Any
2031 ): -> 2032 return arraylike.array_ufunc(self, ufunc, method, *inputs, **kwargs) 2033 2034 # ideally we would define this to avoid the getattr checks, but~\anaconda3\lib\site-packages\pandas\core\arraylike.py in array_ufunc(self, ufunc, method, *inputs, **kwargs) 251 252 # for binary ops, use our custom dunder methods --> 253 result = maybe_dispatch_ufunc_to_dunder_op(self, ufunc, method, *inputs, **kwargs) 254 if result is not NotImplemented: 255 return result
~\anaconda3\lib\site-packages\pandas_libs\ops_dispatch.pyx in pandas._libs.ops_dispatch.maybe_dispatch_ufunc_to_dunder_op()
~\anaconda3\lib\site-packages\pandas\core\ops\common.py in new_method(self, other) 67 other = item_from_zerodim(other) 68 ---> 69 return method(self, other) 70 71 return new_method
~\anaconda3\lib\site-packages\pandas\core\arraylike.py in ror(self, other) 72 @unpack_zerodim_and_defer("ror") 73 def ror(self, other): ---> 74 return self.logical_method(other, roperator.ror) 75 76 @unpack_zerodim_and_defer("xor")
~\anaconda3\lib\site-packages\pandas\core\frame.py in _arith_method(self, other, op) 6864 self, other = ops.align_method_FRAME(self, other, axis, flex=True, level=None)
6865 -> 6866 new_data = self._dispatch_frame_op(other, op, axis=axis) 6867 return self._construct_result(new_data)
6868~\anaconda3\lib\site-packages\pandas\core\frame.py in _dispatch_frame_op(self, right, func, axis) 6891 # i.e. scalar, faster than checking np.ndim(right) == 0 6892
with np.errstate(all="ignore"): -> 6893 bm = self._mgr.apply(array_op, right=right) 6894 return type(self)(bm) 6895~\anaconda3\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, align_keys, ignore_failures, **kwargs) 323 try: 324 if callable(f): --> 325 applied = b.apply(f, **kwargs) 326 else: 327 applied = getattr(b, f)(**kwargs)
~\anaconda3\lib\site-packages\pandas\core\internals\blocks.py in apply(self, func, **kwargs) 379 """ 380 with np.errstate(all="ignore"): --> 381 result = func(self.values, **kwargs) 382 383 return self._split_op_result(result)
~\anaconda3\lib\site-packages\pandas\core\ops\array_ops.py in logical_op(left, right, op) 390 filler = fill_int if is_self_int_dtype and is_other_int_dtype else fill_bool 391 --> 392 res_values = na_logical_op(lvalues, rvalues, op) 393 # error: Cannot call function of unknown type 394 res_values = filler(res_values) # type: ignore[operator]
~\anaconda3\lib\site-packages\pandas\core\ops\array_ops.py in na_logical_op(x, y, op) 323 ) as err: 324 typ = type(y).name --> 325 raise TypeError( 326 f"Cannot perform '{op.name}' with a dtyped [{x.dtype}] array " 327 f"and scalar of type [{typ}]"
TypeError: Cannot perform 'ror_' with a dtyped [float64] array and scalar of type [bool]
The error is very long but from what I may understand, the problem comes from the second condition which is not compatible with an 'OR' ( | ).
Do you guys have any idea how I could do what I intend to please? The only thing I can see is to create a new column with current index names, so that si filtering might work with the OR condition.
CodePudding user response:
IIUC, use:
m1 = final_set['Indicator Name'].eq('GDP per capita (constant 2005 US$)')
m2 = fina_set['2013'] >= gdp_min
countries = list(final_set.index[m1 & m2]) ['China', 'India', 'Brazil']
gdp_set = final_set[final_set.index.isin(countries)]
CodePudding user response:
UPDATED:
This should do what you're asking:
gdp_set = final_set.loc[list(
{'China', 'India', 'Brazil'} |
set(final_set[((final_set['Indicator Name'] == 'GDP per capita (constant 2005 US$)') &
(final_set['2013'] >= gdp_min))].index)
)]
Explanation:
- create a
setcontaining the union of'China', 'India', 'Brazil'with thesetof any index values (i.e.,Country Namevalues) for rows where value ofIndicator Namematches the target and value of2013column is at least as large asgdp_min. - filter
final_seton the countries in thissetconverted to alistand put the resulting dataframe ingdp_set.
Full test code:
import pandas as pd
final_set = pd.DataFrame({
'Country Name':['Andorra']*6 ['Argentina']*4 ['China']*2 ['India']*2 ['Brazil']*2,
'Indicator Name':[f'Indicator {i}' for i in range(1, 6)] ['GDP per capita (constant 2005 US$)'] [f'Indicator {i}' for i in range(1, 4)] ['GDP per capita (constant 2005 US$)'] [f'Indicator {i}'if i % 2 else 'GDP per capita (constant 2005 US$)' for i in range(1,7)],
'2002': [10000.0/2]*6 [15000.0/2]*4 [8000.0/2]*6,
'2013': [10000.0]*6 [15000.0]*4 [8000.0]*6,
'Currency Unit':['Euro']*6 ['Argentine peso']*4 ['RMB']*2 ['INR']*2 ['Brazilian real']*2,
'Region':['Europe & Central Asia']*6 ['Latin America & Caribbean']*4 ['Asia']*2 ['South Asia']*2 ['Latin America & Caribbean']*2,
'GDP per capita (constant 2005 US$)': [10000.0]*6 [15000.0]*4 [8000.0]*6
}).set_index('Country Name')
print(final_set)
gdp_min = 14000.0
gdp_set = final_set.loc[list(
{'China', 'India', 'Brazil'} |
set(final_set[((final_set['Indicator Name'] == 'GDP per capita (constant 2005 US$)') &
(final_set['2013'] >= gdp_min))].index)
)]
print(gdp_set)
Input:
Indicator Name 2002 2013 Currency Unit Region GDP per capita (constant 2005 US$)
Country Name
Andorra Indicator 1 5000.0 10000.0 Euro Europe & Central Asia 10000.0
Andorra Indicator 2 5000.0 10000.0 Euro Europe & Central Asia 10000.0
Andorra Indicator 3 5000.0 10000.0 Euro Europe & Central Asia 10000.0
Andorra Indicator 4 5000.0 10000.0 Euro Europe & Central Asia 10000.0
Andorra Indicator 5 5000.0 10000.0 Euro Europe & Central Asia 10000.0
Andorra GDP per capita (constant 2005 US$) 5000.0 10000.0 Euro Europe & Central Asia 10000.0
Argentina Indicator 1 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
Argentina Indicator 2 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
Argentina Indicator 3 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
Argentina GDP per capita (constant 2005 US$) 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
China Indicator 1 4000.0 8000.0 RMB Asia 8000.0
China GDP per capita (constant 2005 US$) 4000.0 8000.0 RMB Asia 8000.0
India Indicator 3 4000.0 8000.0 INR South Asia 8000.0
India GDP per capita (constant 2005 US$) 4000.0 8000.0 INR South Asia 8000.0
Brazil Indicator 5 4000.0 8000.0 Brazilian real Latin America & Caribbean 8000.0
Brazil GDP per capita (constant 2005 US$) 4000.0 8000.0 Brazilian real Latin America & Caribbean 8000.0
Output:
Indicator Name 2002 2013 Currency Unit Region GDP per capita (constant 2005 US$)
Country Name
Brazil Indicator 5 4000.0 8000.0 Brazilian real Latin America & Caribbean 8000.0
Brazil GDP per capita (constant 2005 US$) 4000.0 8000.0 Brazilian real Latin America & Caribbean 8000.0
China Indicator 1 4000.0 8000.0 RMB Asia 8000.0
China GDP per capita (constant 2005 US$) 4000.0 8000.0 RMB Asia 8000.0
India Indicator 3 4000.0 8000.0 INR South Asia 8000.0
India GDP per capita (constant 2005 US$) 4000.0 8000.0 INR South Asia 8000.0
Argentina Indicator 1 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
Argentina Indicator 2 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
Argentina Indicator 3 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
Argentina GDP per capita (constant 2005 US$) 7500.0 15000.0 Argentine peso Latin America & Caribbean 15000.0
CodePudding user response:
How about using a query?
# min GDP (I used an example number
gdp_min = 3000.0
# Country name set.
countries = {"China", "India", "Brazil"}
# Create string expression to evaluate on DataFrame.
# Note: Backticks should be used for non-standard pandas field names
# (including names that begin with a numerical value.
expression = f"(`Indicator Name` == 'GDP per capita (constant 2005 US$)' & `2013` >= {gdp_min})"
# Add each country name as 'or' clause for second part of expression.
expression = "or (" " or ".join([f"`Country Name` == '{n}'" for n in countries]) ")"
# Collect resulting DataFrame to new variable.
gdp_set = final_set.query(expression)