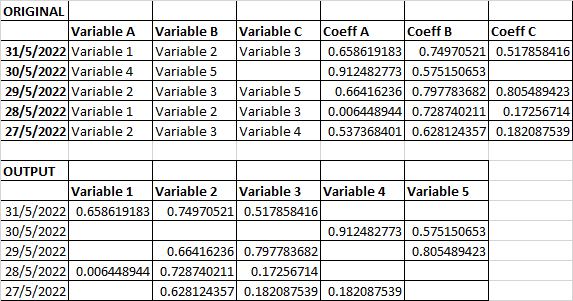
What would be a efficient pythonic way to re-arrange a dataframe as such? I'm attempting a regression analysis, unfortunately the data is formatted this way. At this time I am using iterations to cut and merge the dataframe (several hundred rows), but it is slow and messy. Thanks!
CodePudding user response:
Using pandas:
import pandas as pd
# your dataframe example with truncated values and names
df = pd.DataFrame(
{
'VarA': ['Var1', 'Var4', 'Var2', 'Var1', 'Var2'],
'VarB': ['Var2', 'Var5', 'Var3', 'Var2', 'Var3'],
'VarC': ['Var3', None, 'Var5', 'Var3', 'Var4'],
'CoefA': [0.658, 0.912, 0.664, 0.006, 0.537],
'CoefB': [0.749, 0.575, 0.797, 0.728, 0.628],
'CoefC': [0.517, None, 0.805, 0.172, 0.182]
},
index=pd.date_range('5/27/22','5/31/22')[::-1]
)
df
# VarA VarB VarC CoefA CoefB CoefC
# 2022-05-31 Var1 Var2 Var3 0.658 0.749 0.517
# 2022-05-30 Var4 Var5 None 0.912 0.575 NaN
# 2022-05-29 Var2 Var3 Var5 0.664 0.797 0.805
# 2022-05-28 Var1 Var2 Var3 0.006 0.728 0.172
# 2022-05-27 Var2 Var3 Var4 0.537 0.628 0.182
Convert each pair of name and value columns into proper format, dropping rows with null values:
c_A = (df[['VarA','CoefA']]
.dropna()
.pivot(columns='VarA')
.droplevel(0, axis=1)
.rename_axis(None, axis=1)
)
c_B = (df[['VarB','CoefB']]
.dropna()
.pivot(columns='VarB')
.droplevel(0, axis=1)
.rename_axis(None, axis=1)
)
c_C = (df[['VarC','CoefC']]
.dropna()
.pivot(columns='VarC')
.droplevel(0, axis=1)
.rename_axis(None, axis=1)
)
c_C
# Var3 Var4 Var5
# 2022-05-27 NaN 0.182 NaN
# 2022-05-28 0.172 NaN NaN
# 2022-05-29 NaN NaN 0.805
# 2022-05-31 0.517 NaN NaN
Combine the three dataframes into one, updating values in columns with same name, and then reversing the order of rows to match your desired result:
res = c_A.combine_first(c_B).combine_first(c_C).iloc[::-1]
res
# Var1 Var2 Var3 Var4 Var5
# 2022-05-31 0.658 0.749 0.517 NaN NaN
# 2022-05-30 NaN NaN NaN 0.912 0.575
# 2022-05-29 NaN 0.664 0.797 NaN 0.805
# 2022-05-28 0.006 0.728 0.172 NaN NaN
# 2022-05-27 NaN 0.537 0.628 0.182 NaN
CodePudding user response:
Try this:
import pandas as pd
data = pd.DataFrame({
'VarA': ['Var1', 'Var4', 'Var2', 'Var1', 'Var2'],
'VarB': ['Var2', 'Var5', 'Var3', 'Var2', 'Var3'],
'VarC': ['Var3', None, 'Var5', 'Var3', 'Var4'],
'CoefA': [0.658, 0.912, 0.664, 0.006, 0.537],
'CoefB': [0.749, 0.575, 0.797, 0.728, 0.628],
'CoefC': [0.517, None, 0.805, 0.172, 0.182]},
index=['2022-05-31', '2022-05-30', '2022-05-29', '2022-05-28','2022-05-27'])
## Crete new dataframe with headers
res = pd.DataFrame(columns=['Var1', 'Var2', 'Var3', 'Var4', 'Var5'])
## Parse each row in original data and insert value to new dataframe
for idx, row in data.iterrows():
res.at[idx, row['VarA']] = row['CoefA']
res.at[idx, row['VarB']] = row['CoefB']
res.at[idx, row['VarC']] = row['CoefC']
## Remove unwanted columns (None)
res = res[['Var1', 'Var2', 'Var3', 'Var4', 'Var5']]
Output:
| Var1 | Var2 | Var3 | Var4 | Var5 | |
|---|---|---|---|---|---|
| 2022-05-31 | 0.658 | 0.749 | 0.517 | NaN | NaN |
| 2022-05-30 | NaN | NaN | NaN | 0.912 | 0.575 |
| 2022-05-29 | NaN | 0.664 | 0.797 | NaN | 0.805 |
| 2022-05-28 | 0.006 | 0.728 | 0.172 | NaN | NaN |
| 2022-05-27 | NaN | 0.537 | 0.628 | 0.182 | NaN |
The logic is to iter and parse each row in the original dataframe, then insert the value to corresponding location in the new dataframe (res in my code)
p.s. As there is a None in VarC, there will be a column None in res with this script, therefore the last line is to only select wanted columns