I am working with a wide data set resembling the following:
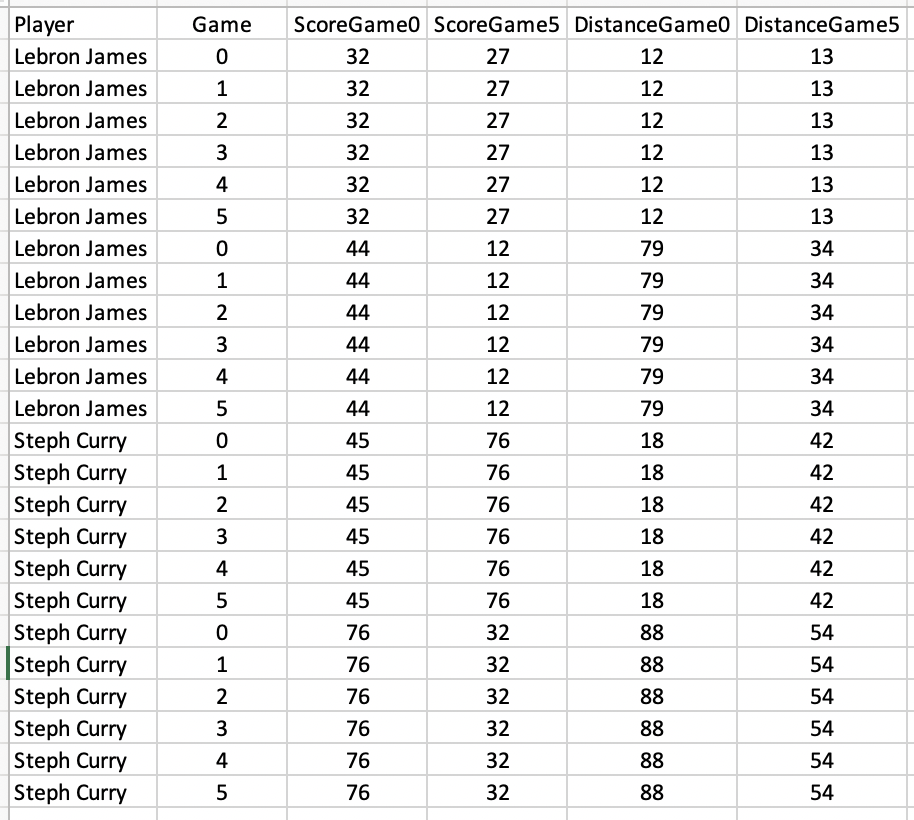
I am looking to write a function that I can iterate over sets of columns with similar names, but with different names. For the sake of simplicity here in terms of the function itself, I'll just create a function that takes the mean of two columns.
avg <- function(data, scorecol, distcol) {
ScoreDistanceAvg = (scorecol distcol)/2
data$ScoreDistanceAvg <- ScoreDistanceAvg
return(data)
}
avg(data = dat, scorecol = dat$ScoreGame0, distcol = dat$DistanceGame0)
How can I apply the new function to sets of columns with repeated names but different numbers? That is, how could I create a column that takes the mean of ScoreGame0 and DistanceGame0, then create a column that takes the mean of ScoreGame5 and DistanceGame5, and so on? This would be the final output:
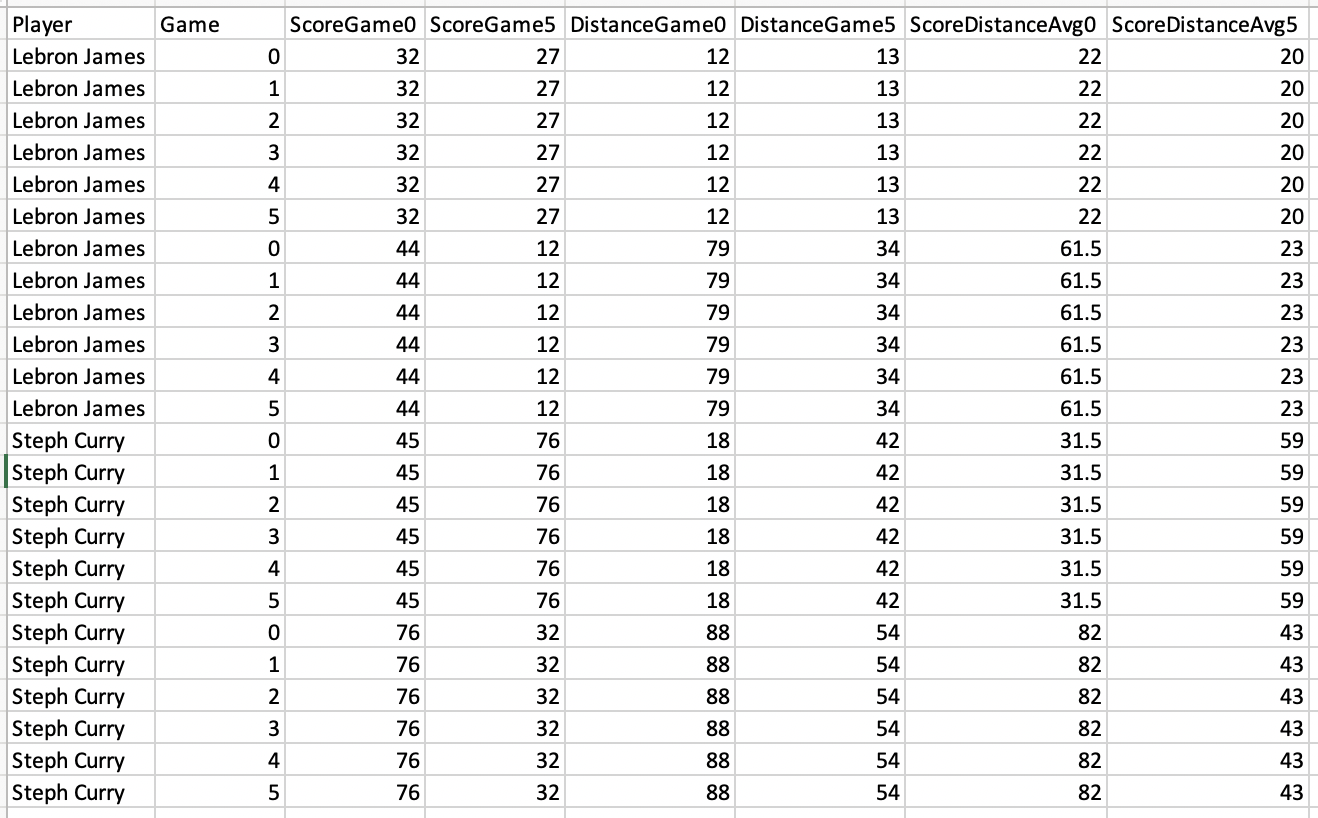
Of course, I could just run the function multiple times, but since my full data set is much larger, how could I automate this process? I imagine it involves apply, but I'm not sure how to use apply with a repeated pattern like that. Additionally, I imagine it may involve rewriting the function to better automate the naming of columns.
Data:
structure(list(Player = c("Lebron James", "Lebron James", "Lebron James",
"Lebron James", "Lebron James", "Lebron James", "Lebron James",
"Lebron James", "Lebron James", "Lebron James", "Lebron James",
"Lebron James", "Steph Curry", "Steph Curry", "Steph Curry",
"Steph Curry", "Steph Curry", "Steph Curry", "Steph Curry", "Steph Curry",
"Steph Curry", "Steph Curry", "Steph Curry", "Steph Curry"),
Game = c(0L, 1L, 2L, 3L, 4L, 5L, 0L, 1L, 2L, 3L, 4L, 5L,
0L, 1L, 2L, 3L, 4L, 5L, 0L, 1L, 2L, 3L, 4L, 5L), ScoreGame0 = c(32L,
32L, 32L, 32L, 32L, 32L, 44L, 44L, 44L, 44L, 44L, 44L, 45L,
45L, 45L, 45L, 45L, 45L, 76L, 76L, 76L, 76L, 76L, 76L), ScoreGame5 = c(27L,
27L, 27L, 27L, 27L, 27L, 12L, 12L, 12L, 12L, 12L, 12L, 76L,
76L, 76L, 76L, 76L, 76L, 32L, 32L, 32L, 32L, 32L, 32L), DistanceGame0 = c(12L,
12L, 12L, 12L, 12L, 12L, 79L, 79L, 79L, 79L, 79L, 79L, 18L,
18L, 18L, 18L, 18L, 18L, 88L, 88L, 88L, 88L, 88L, 88L), DistanceGame5 = c(13L,
13L, 13L, 13L, 13L, 13L, 34L, 34L, 34L, 34L, 34L, 34L, 42L,
42L, 42L, 42L, 42L, 42L, 54L, 54L, 54L, 54L, 54L, 54L)), class = "data.frame", row.names = c(NA,
-24L))
CodePudding user response:
Rewrite your function slightly and use it in mapply by greping over the columns. sort makes this even safer.
avg <- function(scorecol, distcol) {
(scorecol distcol)/2
}
mapply(avg, dat[sort(grep('ScoreGame', names(dat)))], dat[sort(grep('DistanceGame', names(dat)))])
# ScoreGame0 ScoreGame5
# [1,] 22.0 20
# [2,] 22.0 20
# [3,] 22.0 20
# [4,] 22.0 20
# [5,] 22.0 20
# [6,] 22.0 20
# [7,] 61.5 23
# [8,] 61.5 23
# [9,] 61.5 23
# [10,] 61.5 23
# [11,] 61.5 23
# [12,] 61.5 23
# [13,] 31.5 59
# [14,] 31.5 59
# [15,] 31.5 59
# [16,] 31.5 59
# [17,] 31.5 59
# [18,] 31.5 59
# [19,] 82.0 43
# [20,] 82.0 43
# [21,] 82.0 43
# [22,] 82.0 43
# [23,] 82.0 43
# [24,] 82.0 43
To see what grep does try
grep('DistanceGame', names(dat), value=TRUE)
# [1] "DistanceGame0" "DistanceGame5"
CodePudding user response:
Here's a solution with a forloop and dplyr:
library(dplyr)
library(readr)
game_num <- names(dat) %>%
readr::parse_number() %>%
na.omit()
for(i in unique(game_num)) {
avg <- paste0("ScoreDistanceAvg", i)
score <- paste0("ScoreGame", i)
distance <- paste0("DistanceGame", i)
dat[[avg]] <- (dat[[score]] dat[[distance]])/2
}
Which gives:
Player Game ScoreGame0 ScoreGame5 DistanceGame0 DistanceGame5 ScoreDistanceAvg0 ScoreDistanceAvg5
1 Lebron James 0 32 27 12 13 22.0 20
2 Lebron James 1 32 27 12 13 22.0 20
3 Lebron James 2 32 27 12 13 22.0 20
4 Lebron James 3 32 27 12 13 22.0 20
5 Lebron James 4 32 27 12 13 22.0 20
6 Lebron James 5 32 27 12 13 22.0 20
7 Lebron James 0 44 12 79 34 61.5 23
8 Lebron James 1 44 12 79 34 61.5 23
9 Lebron James 2 44 12 79 34 61.5 23
10 Lebron James 3 44 12 79 34 61.5 23
11 Lebron James 4 44 12 79 34 61.5 23
12 Lebron James 5 44 12 79 34 61.5 23
13 Steph Curry 0 45 76 18 42 31.5 59
CodePudding user response:
in Base R:
cols_used <- names(df[, -(1:2)])
f <- sub("[^0-9] ", 'ScoreDistance', cols_used)
data.frame(lapply(split.default(df[cols_used], f), rowMeans))
ScoreDistance0 ScoreDistance5
1 22.0 20
2 22.0 20
3 22.0 20
4 22.0 20
5 22.0 20
6 22.0 20
7 61.5 23
8 61.5 23
9 61.5 23
10 61.5 23
11 61.5 23
12 61.5 23
13 31.5 59
14 31.5 59
15 31.5 59
16 31.5 59
17 31.5 59
18 31.5 59
19 82.0 43
20 82.0 43
21 82.0 43
22 82.0 43
23 82.0 43
24 82.0 43
Using tidyverse: