I can't find a way to show the most frequent number in this list
a = [1,2,4,5,6,7,15,16,19,23,24,26,27,28,29,30,31,33,36,37,38,39,40,41,42,43,44,45,47,48,49,50,51,52,56,57,58,60]
b = [1,3,4,5,6,8,9,10,15,16,17,18,20,21,22,24,26,28,29,31,32,33,36,37,38,40,41,43,44,47,48,50,52,53,54,56,57,58,60]
c = [2,3,5,6,8,9,12,13,17,19,20,23,25,26,27,28,29,30,31,33,34,35,36,37,40,44,45,47,48,52,53,54,55,56,57,58,60]
d = [2,5,7,9,11,12,13,14,16,18,20,22,23,26,29,30,33,34,36,38,40,41,42,43,44,46,47,49,50,51,53,56,57,58,60]
list_1 = [a,b]
list_2 = [c,d]
lists = [list_1, list_2]
I have tried the collections library with the most_common() funtion but it does't seem to work. Same happens with numpy arrays.
It would be perfect if I could get the top 10 most common number too.
The reason for the list to be multi-dimensional is for easy comparison between months
Jan_22 = [jan_01, jan_02, jan_03, jan_04]
Fev_22 = [fev_01, fev_02, fev_03, fev_04]
months = [Fev_22, Jan_22]
Each month has 4 data sets, making those lists allows me to compare big chunks of data, Top 10 most common values from 2021, most common number in jan, fev, mar, April, may ,jun. Would make it easier and clear
Thanks
CodePudding user response:
Maybe I don't fully understand your question, but I don't understand why the list needs to be multi-dimensional if you only want to know the frequency of a given value.
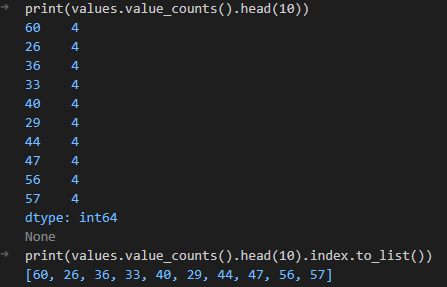
import pandas as pd
a = [1,2,4,5,6,7,15,16,19,23,24,26,27,28,29,30,31,33,36,37,38,39,40,41,42,43,44,45,47,48,49,50,51,52,56,57,58,60]
b = [1,3,4,5,6,8,9,10,15,16,17,18,20,21,22,24,26,28,29,31,32,33,36,37,38,40,41,43,44,47,48,50,52,53,54,56,57,58,60]
c = [2,3,5,6,8,9,12,13,17,19,20,23,25,26,27,28,29,30,31,33,34,35,36,37,40,44,45,47,48,52,53,54,55,56,57,58,60]
d = [2,5,7,9,11,12,13,14,16,18,20,22,23,26,29,30,33,34,36,38,40,41,42,43,44,46,47,49,50,51,53,56,57,58,60]
values = pd.Series(a b c d)
print(values.value_counts().head(10))
print(values.value_counts().head(10).index.to_list())
CodePudding user response:
I dont get why are you adding up lists in each step to get a 3D element, you could just use arrays or smth like that, but here is a function that does what you want in a 3d list (returns the x most common elements in your 3d list ,a.k.a list of lists):
import numpy as np
arr = [[1,2,4,5,6,7,15,16,19,23,24,26,27,28,29,30,31,33,36,37,38,39,40,41,42,43,44,45,47,48,49,50,51,52,56,57,58,60],
[1,3,4,5,6,8,9,10,15,16,17,18,20,21,22,24,26,28,29,31,32,33,36,37,38,40,41,43,44,47,48,50,52,53,54,56,57,58,60],
[2,3,5,6,8,9,12,13,17,19,20,23,25,26,27,28,29,30,31,33,34,35,36,37,40,44,45,47,48,52,53,54,55,56,57,58,60],
[2,5,7,9,11,12,13,14,16,18,20,22,23,26,29,30,33,34,36,38,40,41,42,43,44,46,47,49,50,51,53,56,57,58,60]]
def x_most_common(arr, x):
l = [el for l in arr for el in l]
output = list(set([(el, l.count(el)) for el in l]))
output.sort(key= lambda i: i[1], reverse=True)
return output[:x]
# test:
print(x_most_common(arr, 5))
output:
[(56, 4), (36, 4), (47, 4), (58, 4), (5, 4)]