I am trying to solve a homework example at parallel computing. Here is the given code snippet:
for (int i=0; i < n-1; i ) {
x[i] = (y[i] x[i 1]) / 7;
}
We have to analyze the code snippet regarding dependencies and try to parallelize the given snippet and benchmark it with a propper sample size. My first try was just to copy x and remove the anti dependence here:
double *x_old = malloc(sizeof(*x_old) * n); // the plain "copy" of x
memcpy(x_old, &x[1], (n - 1) * sizeof(*x)); // to prevent i 1 in loop we start x[1] and copy n - 1 elements
#pragma omp parallel for
for (int i = 0; i < n-1; i ) {
x[i] = (y[i] x_old[i]) / 7;
}
this code works, i checked the serial and parallel checksums of the array and they are both the same. The speedup without calculating the memcpy() in is between 1.6 - 2 for 100_000_00 - 400_000_000 array elements. But if I increase the array size further (at arround 470_000_000 elements) the speedup decreases significantly and at 500_000_000 array elements the speedup is 0.375.
It is irrelevant how many threads I use.
I benchmarked it on 3 different devices with the same result (speedup wise):
Lenovo Ideapad 5

Desktop PC

and at our cluster node PC

Why is there a drop in speedup and why does it drops so fast? Why does this happen at that specific size of the array?
I provide a minimum example of the programm here:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
#include "omp.h"
void init(double *arr, int size);
double sum(double *arr, int size);
int main(int argc, char **argv){
if(argc != 3){
printf("Wrong use of program! (1) Size of array, (2) num threads\n");
return EXIT_FAILURE;
}
int n = atoi(argv[1]);
int threads = atoi(argv[2]);
omp_set_num_threads(threads);
double *x = malloc(sizeof(*x) * n);
double *y = malloc(sizeof(*y) * n);
init(x, n);
init(y, n);
double start = omp_get_wtime();
for (int i = 0; i < n-1; i ) {
x[i] = (y[i] x[i 1]) / 7;
}
double end = omp_get_wtime();
double elapsed_s = end - start;
printf("single elapsed: %fs\n", elapsed_s);
double checksum_s = sum(x, n);
printf("single checksum: %f\n", checksum_s);
init(x, n); //reinit
init(y, n); //reinit
double *x_old = malloc(sizeof(*x_old) * n); // the plain "copy" of x
memcpy(x_old, &x[1], (n - 1) * sizeof(*x)); // to prevent i 1 in loop we start x[1] and copy n - 1 elements
start = omp_get_wtime();
#pragma omp parallel for
for (int i = 0; i < n-1; i ) {
x[i] = (y[i] x_old[i]) / 7;
}
end = omp_get_wtime();
double elapsed_p = end - start;
printf("omp threads %d Thread(s) elapsed: %fs\n", omp_get_max_threads(), elapsed_p);
double checksum_p = sum(x, n);
printf("omp threads %d Thread(s) single checksum: %f\n", omp_get_max_threads(), checksum_p);
printf("%s\n", fabs((checksum_p - checksum_s)) < __DBL_EPSILON__ ? "OK" : "FAILED");
printf("Speedup: %.3f\n", elapsed_s / elapsed_p);
}
void init(double *arr, int size){
for(int i = 0; i < size; i){
arr[i] = 1.0;
}
}
double sum(double *arr, int size){
double sum = 0.0;
for(int i = 0; i < size; i){
sum = arr[i];
}
return sum;
}
here a sample benchmark:
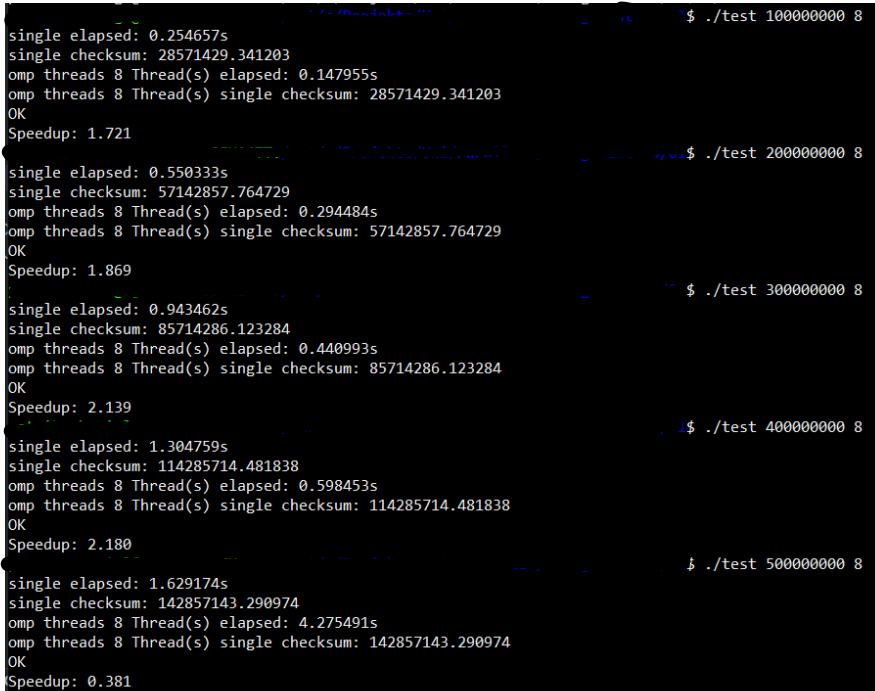
CodePudding user response:
The problem certainly comes from swap memory. Indeed, the code allocates 3 array of 500_000_000 items resulting in 4 GiB of RAM required for each array and 12 GiB overall. The thing is two of the benchmarking machines have only 16 GiB of RAM available and the OS as well as running applications generally require already 1-4 GiB of RAM. When the amount of available physical memory becomes small, the OS starts to move memory pages on a space called swap memory which is typically mapped on your storage device that is far much slower than usual RAM. Note that some operating systems like Windows already use ZRAM so to compress data when the available amount of memory becomes small. Mainstream OS (Windows, Linux and MAC also need some additional space for buffers (eg. storage device buffers, networking, etc.). The allocation of memory pages can also becomes slower when the amount of memory becomes small. Also note that pages are allocated in RAM only during the first touch on mainstream systems. For more information about this, please read this article.
Allocating a huge x_old array is not efficient (in both time and space). Indeed, the memcopy will take a lot of time to copy data in memory and this operation is limited by the throughput of the RAM which is generally low. You can speed up the operation by operating on chunks. The idea is to copy a small data block (of let say 16 KiB) in each thread so the operation can be done in the L1 cache of each core. This means that the cost of the memcpy will nearly vanish since CPU caches are much faster than the RAM (both the latency and the throughput). In fact, the L1 CPU cache of the notebook/desktop computer should be >100 GiB/core, resulting in a cumulated throughput >600 GiB, while the throughput of the RAM should not exceed 40 GiB/s in practice (15x slower).
For the cluster node, it is a bit more complex since it is subject to NUMA effects. NUMA architectures are pretty complex. For more information, I advise you to read this article first, then read Explanation for why effective DRAM bandwidth reduces upon adding CPUs (including the related links) and Problem of sorting OpenMP threads into NUMA nodes by experiment. Put it shortly, you need to care about where the pages are allocated (allocation policy). The key is to control the first touch on pages (on most platforms).
CodePudding user response:
A few issues ...
- Using
x_oldfor parallel (e.g.x, y, x_old) uses 3 arrays instead of 2 (e.g.x, y) puts an additional strain on the memory controller and cache, so the comparison is not valid. The parallel version is at a distinct disadvantage. - You only showed data for single and 8 threads. Your program is memory bus [and cache] bound (rather than compute bound).
- From Atomically increment two integers with CAS follow the video link to a talk: https://www.youtube.com/watch?v=1obZeHnAwz4&t=1251 There the speaker benchmarks similar things. His conclusion was that any more than 4 threads will swamp the memory bus (i.e. any more actually reduces performance). The additional threads just add extra overhead due to the overhead of switching threads, cache misses, and causing less locality of reference.
- Other things in the system can affect the numbers. Other [unrelated] threads/processes can steal CPU time and memory. The kernel overhead of handling devices and interrupts. To minimize the effects of this, each test should be run multiple times (e.g. 10) and we should use the minimum time for each setup.
For example, I just ran your program with: 1000000 8 and got:
single elapsed: 0.008146s
single checksum: 285715.000000
omp threads 8 Thread(s) elapsed: 0.008198s
omp threads 8 Thread(s) single checksum: 285715.000000
OK
Speedup: 0.994
When I ran it with: 1000000 4, I got:
single elapsed: 0.008502s
single checksum: 285715.000000
omp threads 4 Thread(s) elapsed: 0.002677s
omp threads 4 Thread(s) single checksum: 285715.000000
OK
Speedup: 3.176
When I ran it another time with: 1000000 8, I got:
single elapsed: 0.008450s
single checksum: 285715.000000
omp threads 8 Thread(s) elapsed: 0.005630s
omp threads 8 Thread(s) single checksum: 285715.000000
OK
Speedup: 1.501
So, 4 is faster than 8. And, two runs of 8 produced [wildly] differing results.
UPDATE:
I refactored the program to run multiple tests as mentioned above:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
#include "omp.h"
void init(double *arr, int size);
double sum(double *arr, int size);
double *x;
double *y;
typedef void (*fnc_p)(double *x,double *y,int n);
void
dosingle(double *x,double *y,int n)
{
for (int i = 0; i < n - 1; i ) {
x[i] = (y[i] x[i 1]) / 7;
}
}
void
doparallel(double *x,double *y,int n)
{
#pragma omp parallel for
for (int i = 0; i < n - 1; i ) {
x[i] = (y[i] x[i 1]) / 7;
}
}
double
timeone(double *x,double *y,int n,fnc_p fnc)
{
init(x, n);
init(y, n);
double start = omp_get_wtime();
fnc(x,y,n);
double end = omp_get_wtime();
double elapsed = end - start;
printf(" elapsed: %fs", elapsed);
double checksum = sum(x, n);
printf(" checksum: %f\n", checksum);
return elapsed;
}
double
timeall(int threads,double *x,double *y,int n,fnc_p fnc,const char *who)
{
omp_set_num_threads(threads);
printf("\n");
printf("threads: %d\n",threads);
double best = 1e9;
for (int irun = 1; irun <= 10; irun) {
printf("%s/%d:",who,irun);
double elapsed = timeone(x,y,n,fnc);
if (elapsed < best)
best = elapsed;
}
return best;
}
int
main(int argc, char **argv)
{
if (argc != 3) {
printf("Wrong use of program! (1) Size of array, (2) num threads\n");
return EXIT_FAILURE;
}
int n = atoi(argv[1]);
int threads = atoi(argv[2]);
x = malloc(sizeof(*x) * n);
y = malloc(sizeof(*y) * n);
double elapsed_s = timeall(1,x,y,n,dosingle,"single");
double best_elapsed = 1e9;
int best_nthread = 0;
for (int ithr = 2; ithr <= threads; ithr) {
double elapsed_p = timeall(ithr,x,y,n,doparallel,"parallel");
printf("Speedup: %.3f\n", elapsed_s / elapsed_p);
if (elapsed_p < best_elapsed) {
best_elapsed = elapsed_p;
best_nthread = ithr;
}
}
printf("\n");
printf("FINAL %d is best with %fs and speedup %.3f\n",
best_nthread,best_elapsed,elapsed_s / best_elapsed);
#if 0
printf("single elapsed: %fs\n", elapsed_s);
double checksum_s = sum(x, n);
printf("single checksum: %f\n", checksum_s);
init(x, n); // reinit
init(y, n); // reinit
double *x_old = malloc(sizeof(*x_old) * n); // the plain "copy" of x
memcpy(x_old, &x[1], (n - 1) * sizeof(*x)); // to prevent i 1 in loop we start x[1] and copy n - 1 elements
start = omp_get_wtime();
#pragma omp parallel for
for (int i = 0; i < n - 1; i ) {
x[i] = (y[i] x_old[i]) / 7;
}
end = omp_get_wtime();
double elapsed_p = end - start;
printf("omp threads %d Thread(s) elapsed: %fs\n", omp_get_max_threads(), elapsed_p);
double checksum_p = sum(x, n);
printf("omp threads %d Thread(s) single checksum: %f\n", omp_get_max_threads(), checksum_p);
printf("%s\n", fabs((checksum_p - checksum_s)) < __DBL_EPSILON__ ? "OK" : "FAILED");
printf("Speedup: %.3f\n", elapsed_s / elapsed_p);
#endif
return 0;
}
void
init(double *arr, int size)
{
for (int i = 0; i < size; i) {
arr[i] = 1.0;
}
}
double
sum(double *arr, int size)
{
double sum = 0.0;
for (int i = 0; i < size; i) {
sum = arr[i];
}
return sum;
}
Here is the test output for: 1000000 16:
threads: 1
single/1: elapsed: 0.008467s checksum: 285715.000000
single/2: elapsed: 0.008178s checksum: 285715.000000
single/3: elapsed: 0.008460s checksum: 285715.000000
single/4: elapsed: 0.008126s checksum: 285715.000000
single/5: elapsed: 0.008250s checksum: 285715.000000
single/6: elapsed: 0.008206s checksum: 285715.000000
single/7: elapsed: 0.007933s checksum: 285715.000000
single/8: elapsed: 0.008440s checksum: 285715.000000
single/9: elapsed: 0.008267s checksum: 285715.000000
single/10: elapsed: 0.008671s checksum: 285715.000000
threads: 2
parallel/1: elapsed: 0.004318s checksum: 285714.897959
parallel/2: elapsed: 0.004216s checksum: 285714.897959
parallel/3: elapsed: 0.004224s checksum: 285714.897959
parallel/4: elapsed: 0.004223s checksum: 285714.897959
parallel/5: elapsed: 0.004201s checksum: 285714.897959
parallel/6: elapsed: 0.004235s checksum: 285714.897959
parallel/7: elapsed: 0.004276s checksum: 285714.897959
parallel/8: elapsed: 0.004161s checksum: 285714.897959
parallel/9: elapsed: 0.004163s checksum: 285714.897959
parallel/10: elapsed: 0.004188s checksum: 285714.897959
Speedup: 1.906
threads: 3
parallel/1: elapsed: 0.002930s checksum: 285714.795918
parallel/2: elapsed: 0.002824s checksum: 285714.795918
parallel/3: elapsed: 0.002788s checksum: 285714.795918
parallel/4: elapsed: 0.002855s checksum: 285714.795918
parallel/5: elapsed: 0.002816s checksum: 285714.795918
parallel/6: elapsed: 0.002800s checksum: 285714.795918
parallel/7: elapsed: 0.002854s checksum: 285714.795918
parallel/8: elapsed: 0.002794s checksum: 285714.795918
parallel/9: elapsed: 0.002807s checksum: 285714.795918
parallel/10: elapsed: 0.002788s checksum: 285714.795918
Speedup: 2.845
threads: 4
parallel/1: elapsed: 0.002296s checksum: 285714.693877
parallel/2: elapsed: 0.002152s checksum: 285714.693877
parallel/3: elapsed: 0.002153s checksum: 285714.693877
parallel/4: elapsed: 0.002122s checksum: 285714.693877
parallel/5: elapsed: 0.002147s checksum: 285714.693877
parallel/6: elapsed: 0.002135s checksum: 285714.693877
parallel/7: elapsed: 0.002135s checksum: 285714.693877
parallel/8: elapsed: 0.002126s checksum: 285714.693877
parallel/9: elapsed: 0.002159s checksum: 285714.693877
parallel/10: elapsed: 0.002156s checksum: 285714.693877
Speedup: 3.738
threads: 5
parallel/1: elapsed: 0.003495s checksum: 285714.591836
parallel/2: elapsed: 0.003311s checksum: 285714.591836
parallel/3: elapsed: 0.003315s checksum: 285714.591836
parallel/4: elapsed: 0.003933s checksum: 285714.591836
parallel/5: elapsed: 0.003397s checksum: 285714.591836
parallel/6: elapsed: 0.003303s checksum: 285714.591836
parallel/7: elapsed: 0.003306s checksum: 285714.591836
parallel/8: elapsed: 0.003371s checksum: 285714.591836
parallel/9: elapsed: 0.003239s checksum: 285714.591836
parallel/10: elapsed: 0.003326s checksum: 285714.591836
Speedup: 2.449
threads: 6
parallel/1: elapsed: 0.002845s checksum: 285714.489795
parallel/2: elapsed: 0.002766s checksum: 285714.489795
parallel/3: elapsed: 0.002774s checksum: 285714.489795
parallel/4: elapsed: 0.002768s checksum: 285714.489795
parallel/5: elapsed: 0.002771s checksum: 285714.489795
parallel/6: elapsed: 0.002779s checksum: 285714.489795
parallel/7: elapsed: 0.002773s checksum: 285714.489795
parallel/8: elapsed: 0.002778s checksum: 285714.489795
parallel/9: elapsed: 0.002767s checksum: 285714.489795
parallel/10: elapsed: 0.002776s checksum: 285714.489795
Speedup: 2.868
threads: 7
parallel/1: elapsed: 0.002559s checksum: 285714.387755
parallel/2: elapsed: 0.002402s checksum: 285714.387755
parallel/3: elapsed: 0.002395s checksum: 285714.387755
parallel/4: elapsed: 0.002392s checksum: 285714.387755
parallel/5: elapsed: 0.002375s checksum: 285714.387755
parallel/6: elapsed: 0.002434s checksum: 285714.387755
parallel/7: elapsed: 0.002373s checksum: 285714.387755
parallel/8: elapsed: 0.002392s checksum: 285714.387755
parallel/9: elapsed: 0.002423s checksum: 285714.387755
parallel/10: elapsed: 0.002387s checksum: 285714.387755
Speedup: 3.342
threads: 8
parallel/1: elapsed: 0.002231s checksum: 285714.285714
parallel/2: elapsed: 0.002112s checksum: 285714.285714
parallel/3: elapsed: 0.002141s checksum: 285714.285714
parallel/4: elapsed: 0.002151s checksum: 285714.285714
parallel/5: elapsed: 0.002149s checksum: 285714.285714
parallel/6: elapsed: 0.002130s checksum: 285714.285714
parallel/7: elapsed: 0.002132s checksum: 285714.285714
parallel/8: elapsed: 0.002136s checksum: 285714.285714
parallel/9: elapsed: 0.002117s checksum: 285714.285714
parallel/10: elapsed: 0.002130s checksum: 285714.285714
Speedup: 3.756
threads: 9
parallel/1: elapsed: 0.003113s checksum: 285714.183673
parallel/2: elapsed: 0.002705s checksum: 285714.183673
parallel/3: elapsed: 0.002863s checksum: 285714.183673
parallel/4: elapsed: 0.002834s checksum: 285714.285714
parallel/5: elapsed: 0.002743s checksum: 285714.183673
parallel/6: elapsed: 0.002759s checksum: 285714.183673
parallel/7: elapsed: 0.002725s checksum: 285714.285714
parallel/8: elapsed: 0.002851s checksum: 285714.183673
parallel/9: elapsed: 0.002587s checksum: 285714.183673
parallel/10: elapsed: 0.002873s checksum: 285714.183673
Speedup: 3.067
threads: 10
parallel/1: elapsed: 0.002834s checksum: 285714.081632
parallel/2: elapsed: 0.003325s checksum: 285714.183673
parallel/3: elapsed: 0.002662s checksum: 285714.183673
parallel/4: elapsed: 0.002531s checksum: 285714.081632
parallel/5: elapsed: 0.003410s checksum: 285714.081632
parallel/6: elapsed: 0.003395s checksum: 285714.081632
parallel/7: elapsed: 0.003235s checksum: 285714.183673
parallel/8: elapsed: 0.002927s checksum: 285714.081632
parallel/9: elapsed: 0.002515s checksum: 285714.081632
parallel/10: elapsed: 0.002818s checksum: 285714.081632
Speedup: 3.154
threads: 11
parallel/1: elapsed: 0.002993s checksum: 285713.979591
parallel/2: elapsed: 0.002404s checksum: 285714.081632
parallel/3: elapsed: 0.002373s checksum: 285714.081632
parallel/4: elapsed: 0.002457s checksum: 285714.183673
parallel/5: elapsed: 0.003038s checksum: 285714.285714
parallel/6: elapsed: 0.002367s checksum: 285714.081632
parallel/7: elapsed: 0.002365s checksum: 285714.081632
parallel/8: elapsed: 0.002999s checksum: 285714.081632
parallel/9: elapsed: 0.003064s checksum: 285714.183673
parallel/10: elapsed: 0.002399s checksum: 285713.979591
Speedup: 3.354
threads: 12
parallel/1: elapsed: 0.002355s checksum: 285714.081632
parallel/2: elapsed: 0.002515s checksum: 285713.877551
parallel/3: elapsed: 0.002774s checksum: 285713.979591
parallel/4: elapsed: 0.002742s checksum: 285713.877551
parallel/5: elapsed: 0.002773s checksum: 285713.979591
parallel/6: elapsed: 0.002722s checksum: 285713.979591
parallel/7: elapsed: 0.002909s checksum: 285714.183673
parallel/8: elapsed: 0.002785s checksum: 285713.877551
parallel/9: elapsed: 0.002741s checksum: 285713.979591
parallel/10: elapsed: 0.002825s checksum: 285714.081632
Speedup: 3.369
threads: 13
parallel/1: elapsed: 0.002908s checksum: 285713.877551
parallel/2: elapsed: 0.002379s checksum: 285713.979591
parallel/3: elapsed: 0.002554s checksum: 285714.081632
parallel/4: elapsed: 0.002653s checksum: 285713.775510
parallel/5: elapsed: 0.002663s checksum: 285713.979591
parallel/6: elapsed: 0.002602s checksum: 285713.877551
parallel/7: elapsed: 0.002527s checksum: 285713.877551
parallel/8: elapsed: 0.002665s checksum: 285713.979591
parallel/9: elapsed: 0.002766s checksum: 285713.979591
parallel/10: elapsed: 0.002620s checksum: 285713.877551
Speedup: 3.335
threads: 14
parallel/1: elapsed: 0.002617s checksum: 285713.877551
parallel/2: elapsed: 0.002438s checksum: 285713.877551
parallel/3: elapsed: 0.002457s checksum: 285713.979591
parallel/4: elapsed: 0.002503s checksum: 285713.979591
parallel/5: elapsed: 0.002350s checksum: 285713.775510
parallel/6: elapsed: 0.002567s checksum: 285713.877551
parallel/7: elapsed: 0.002492s checksum: 285713.979591
parallel/8: elapsed: 0.002458s checksum: 285713.877551
parallel/9: elapsed: 0.002496s checksum: 285713.979591
parallel/10: elapsed: 0.002547s checksum: 285713.979591
Speedup: 3.376
threads: 15
parallel/1: elapsed: 0.002530s checksum: 285713.979591
parallel/2: elapsed: 0.002396s checksum: 285713.877551
parallel/3: elapsed: 0.002267s checksum: 285713.775510
parallel/4: elapsed: 0.002397s checksum: 285713.775510
parallel/5: elapsed: 0.002280s checksum: 285713.571428
parallel/6: elapsed: 0.002415s checksum: 285713.775510
parallel/7: elapsed: 0.002320s checksum: 285713.775510
parallel/8: elapsed: 0.002266s checksum: 285713.979591
parallel/9: elapsed: 0.002356s checksum: 285713.877551
parallel/10: elapsed: 0.002302s checksum: 285713.979591
Speedup: 3.501
threads: 16
parallel/1: elapsed: 0.002679s checksum: 285713.775510
parallel/2: elapsed: 0.002178s checksum: 285713.775510
parallel/3: elapsed: 0.002171s checksum: 285713.571428
parallel/4: elapsed: 0.002446s checksum: 285713.673469
parallel/5: elapsed: 0.002394s checksum: 285713.673469
parallel/6: elapsed: 0.002475s checksum: 285713.571428
parallel/7: elapsed: 0.002165s checksum: 285713.979591
parallel/8: elapsed: 0.002162s checksum: 285713.673469
parallel/9: elapsed: 0.002222s checksum: 285713.673469
parallel/10: elapsed: 0.002186s checksum: 285713.571428
Speedup: 3.670
FINAL 8 is best with 0.002112s and speedup 3.756