I would like to give my sample data column names. I'd like the columns be named after objective functions and their decision variables like this: f_1, f_2, h, b, l, t
Sample data:
sampler = qmc.LatinHypercube(d=4)
u_bounds = np.array([5.0, 5.0, 10.0, 10.0])
l_bounds = np.array([0.125, 0.125, 0.1, 0.1])
data = sampler.lhs_method(100)*(u_bounds-(l_bounds)) (l_bounds)
Optimisation problem where the column names come from:
def objectives (h,b,l,t):
f1 = 1.10471*(h**2)*l 0.04811*t*b*(14.0 l)
f2 = 2.1952 / (t**3)*b
return f1,f2
Shaping the data for the objective functions:
y=np.zeros((100,2))
for i in range(np.shape(data)[0]):
y[i,0], y[i,1] = objectives(data[i,0], data[i,1], data[i,2], data[i,3])
What I tried:
df = pd.DataFrame(data=data)
df.columns = ["h", "b", "l", "t"]
df.head()
frames = [df, y,]
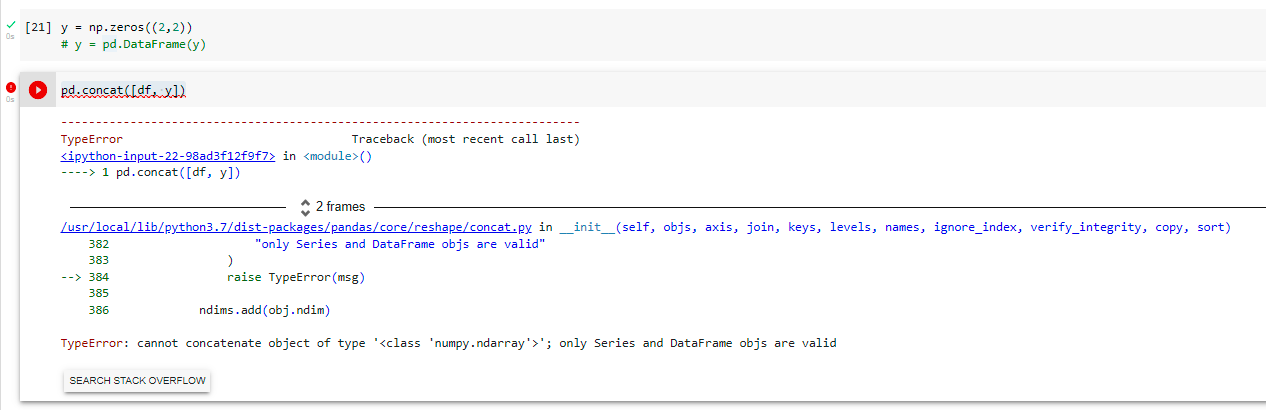
result = pd.concat(frames)
This errors like this: TypeError: cannot concatenate object of type '<class 'numpy.ndarray'>'; only Series and DataFrame objs are valid
So what kind of modifications would you recommend for this problem? Now it looks like these two data frames are not compatible in their current form.
CodePudding user response:
Like the error says, you can't concat a dataframe with a numpy array.
So you should transform y, the numpy array, into a df to concat with another df:
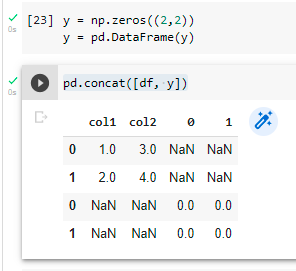
y = np.zeros((2,2))
y = pd.DataFrame(y) #this
pd.concat([df, y])
Reproducing error:
Solving:
CodePudding user response:
If you want them "side by side", you can do something like:
df = pd.DataFrame(data=data)
df.columns = ["h", "b", "l", "t"]
# Adding new colummns from variable y
df['f1'] = y[:,0]
df['f2'] = y[:,1]
# Quick check
df.head()
DataFrames represent tabular data. You can see them as a list of columns where each column has a name (f1, f2, h, b...) and can be accessed/modified through my_dataframe['column_name'].