I was trying to get a data frame of spam messages so I can analyze them. This is what the original CSV file looks like.
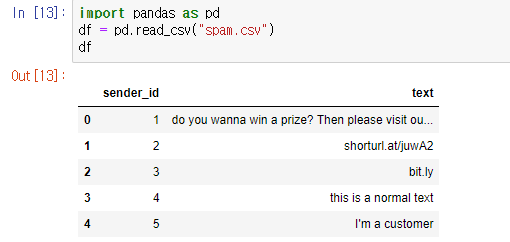
I want it to be like
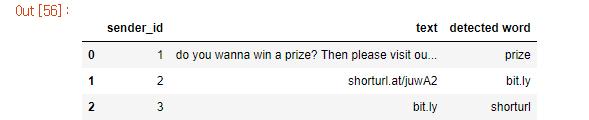
This is what I had tried:
###import the original CSV (it's simplified sample which has only two columns - sender, text)
import pandas as pd
df = pd.read_csv("spam.csv")
### if any of those is in the text column, I'll put that row in the new data frame.
keyword = ["prize", "bit.ly", "shorturl"]
### putting rows that have a keyword into a new data frame.
spam_list = df[df['text'].str.contains('|'.join(keyword))]
### creating a new column 'detected keyword' and trying to show what was detected keyword
spam_list['detected word'] = keyword
spam_list
However, "detected word" is in order of the list. I know it's because I put the list into the new column, but I couldn't think/find a better way to do this. Should I have used "for" as the solution? Or am I approaching it in a totally wrong way?
CodePudding user response:
You can define a function that gets the result for each row:
def detect_keyword(row):
for key in keyword:
if key in row['text']:
return key
then get it done for all rows with pandas.apply() and save results as a new column:
df['detected_word'] = df.apply(lambda x: detect_keyword(x), axis=1)
CodePudding user response:
You can use the code given below in the picture to solve your stated problem, I wasn't able to paste the code because stackoverflow wasn't allowing to paste short links. The link to the code is available.
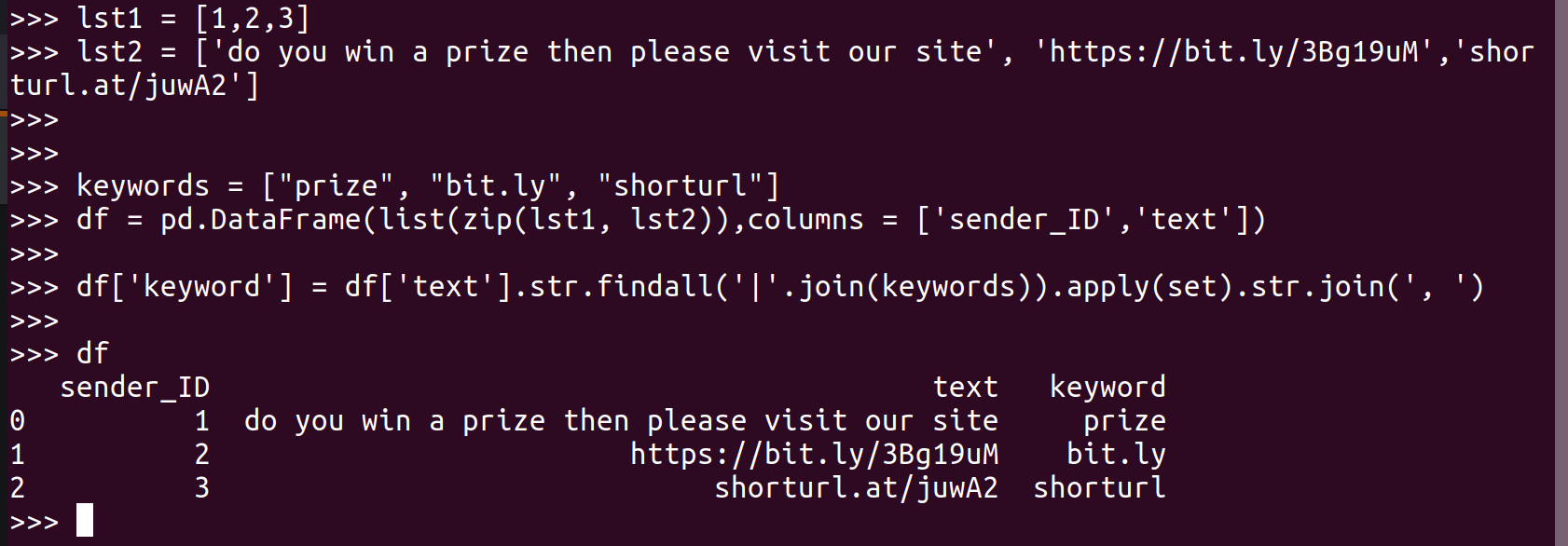
The code has been adapted from here