I have 3 tables likes below erd
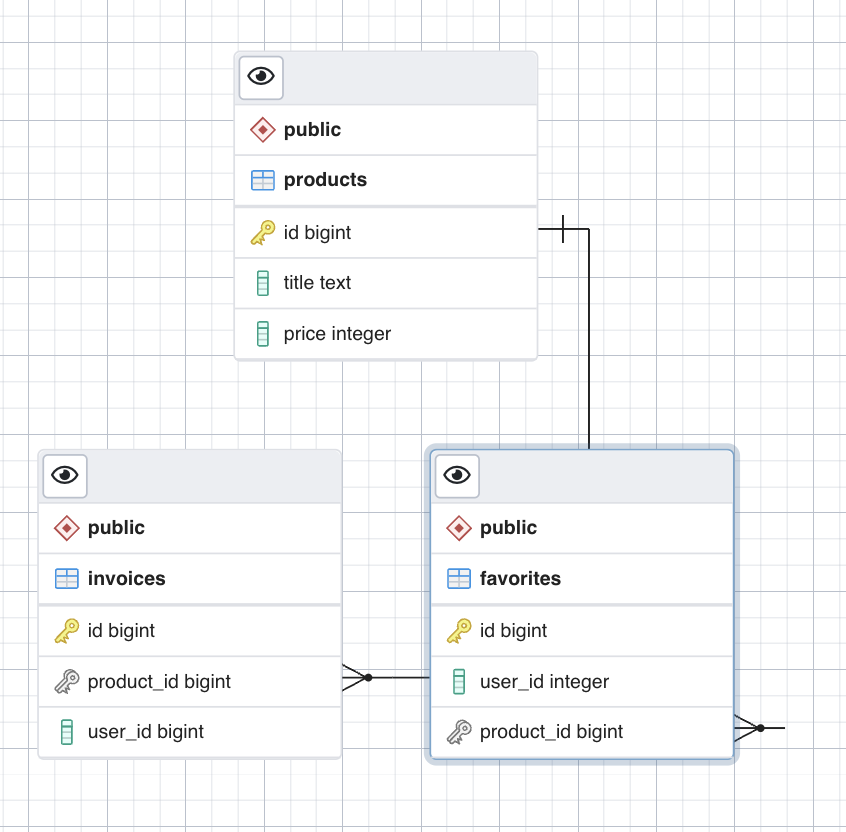
I'm trying to get max number of count product id by desc order count. Then I also add isFavorite depend on user favourites product in favourites table. My expected Json looks like
{
"id": 2,
"title": "30 % discount on pizza.",
"price": 100,
"count": 4,
"isFavorite": false
},
I have tried below query
SELECT PRODUCTS.ID AS "Products__id",
PRODUCTS.TITLE AS "Products__title",
PRODUCTS.PRICE AS "Products__price",
(COUNT(INVOICES.PRODUCT_ID)) AS "count",
CASE
WHEN FAVORITES.USER_ID IS NULL THEN FALSE
ELSE TRUE
END AS "isFavorite"
FROM PRODUCTS PRODUCTS
LEFT JOIN FAVORITES FAVORITES ON FAVORITES.PRODUCT_ID = PRODUCTS.ID
INNER JOIN INVOICES INVOICES ON PRODUCTS.ID = INVOICES.PRODUCT_ID
GROUP BY PRODUCTS.ID,
FAVORITES.USER_ID
ORDER BY COUNT DESC
LIMIT 100
Problem is I'm getting duplicate values
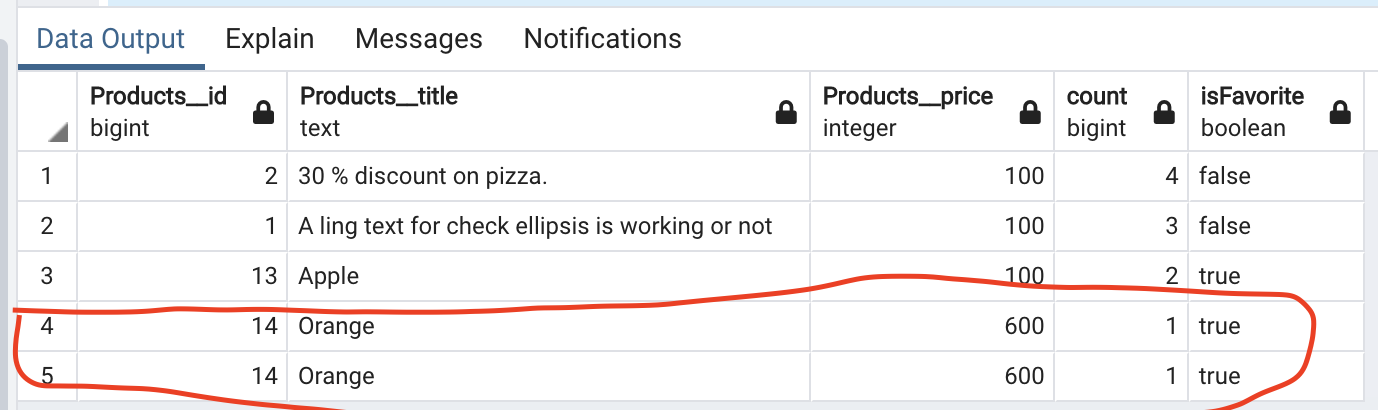
How I will remove this duplicate ?
CodePudding user response:
That will happen if more than one user marks the product as a favorite.
The quick answer is to use an aggregate function on the case statement and remove favorites.user_id from the grouping:
SELECT PRODUCTS.ID AS "Products__id",
PRODUCTS.TITLE AS "Products__title",
PRODUCTS.PRICE AS "Products__price",
COUNT(INVOICES.PRODUCT_ID) AS "count",
BOOL_OR(
CASE
WHEN FAVORITES.USER_ID IS NULL THEN FALSE
ELSE TRUE
END
) AS "isFavorite"
FROM PRODUCTS PRODUCTS
LEFT JOIN FAVORITES FAVORITES
ON FAVORITES.PRODUCT_ID = PRODUCTS.ID
JOIN INVOICES INVOICES
ON INVOICES.PRODUCT_ID = PRODUCTS.ID
GROUP BY PRODUCTS.ID
ORDER BY COUNT DESC
LIMIT 100
Edit to add:
Your original query had
GROUP BY PRODUCTS.ID,
FAVORITES.USER_ID
If a product had more than one user mark it as a favorite, then you would have a row for each distinct FAVORITES.USER_ID.
If you simply removed FAVORITES.USER_ID from the GROUP BY, then you would get an error about how USER_ID has to appear in the GROUP_BY.
I inferred from your query that you want that to be true if any user marked that product as a favorite, so we apply the BOOL_OR() aggregate function that returns true if any true values exist across those rows.