I want to match characters which start with 德州分公司. and end with 公司. My regular expression goes like:
select *
FROM SF_GROUP T
where regexp_like(t.group_name,
'^德州分公司\.([' || unistr('\4e00') || '-' ||
unistr('\9fa5') || ']*)公司$');
-- or another try
select *
FROM SF_GROUP T
where regexp_like(t.group_name,
'^德州分公司\.([\u4e00-\u9fa5]*)公司$');
But neither of the above methods work. The characters to be matched(Chinese characters):
德州分公司.禹城分公司
德州分公司.齐河分公司
德州分公司.综合部
德州分公司.集团客户部
Records in my table:
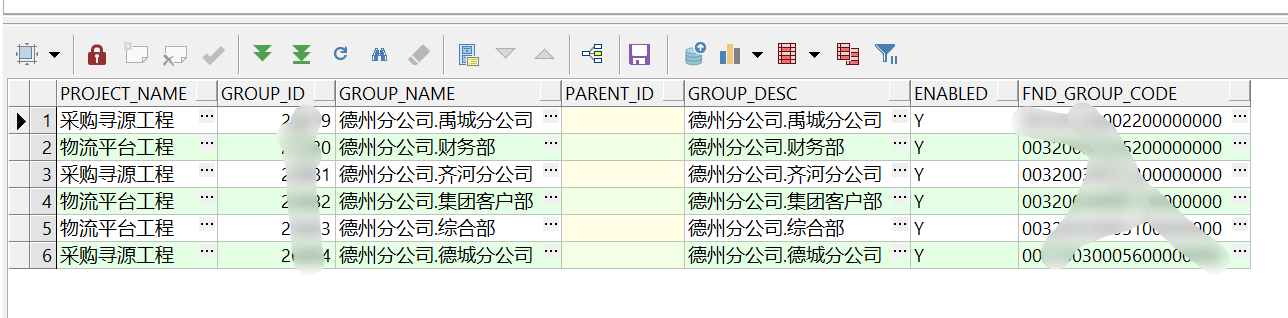
Output I want to get:

However it returns nothing after I excute the sentence:
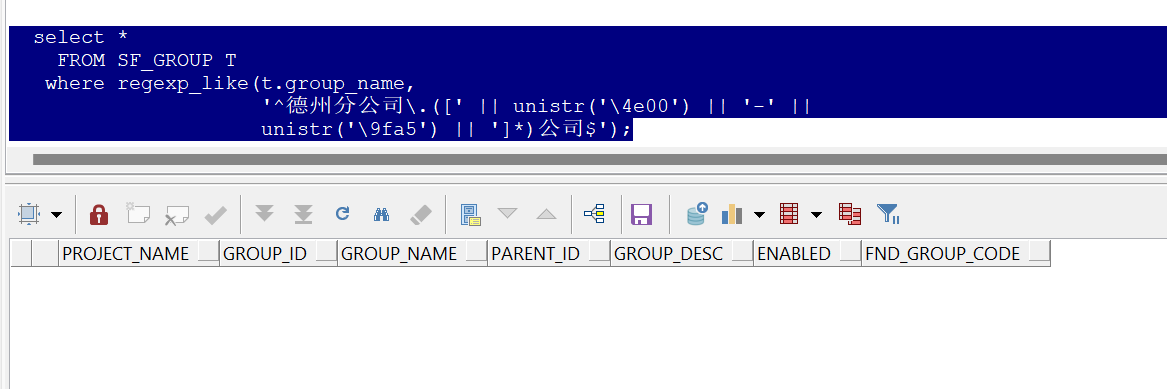
Please help.
CodePudding user response:
you can try this one it should work:
select * FROM SF_GROUP T where regexp_like(t.group_name, '^德州分公司.(.*)公司$');
or you can use LIKE, do not need regular expression:
where t.group_name like('德州分公司%公司')
CodePudding user response:
If you have the data:
CREATE TABLE sf_group (group_name) AS
SELECT '德州分公司.禹城分公司' FROM DUAL UNION ALL
SELECT '德州分公司.齐河分公司' FROM DUAL UNION ALL
SELECT '德州分公司.综合部' FROM DUAL UNION ALL
SELECT '德州分公司.集团客户部' FROM DUAL;
Then:
SELECT group_name,
DUMP(group_name, 1010)
FROM sf_group
Should output something like:
GROUP_NAME DUMP(GROUP_NAME,1010) 德州分公司.禹城分公司 Typ=1 Len=31 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,231,166,185,229,159,142,229,136,134,229,133,172,229,143,184 德州分公司.齐河分公司 Typ=1 Len=31 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,233,189,144,230,178,179,229,136,134,229,133,172,229,143,184 德州分公司.综合部 Typ=1 Len=25 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,231,187,188,229,144,136,233,131,168 德州分公司.集团客户部 Typ=1 Len=31 CharacterSet=AL32UTF8: 229,190,183,229,183,158,229,136,134,229,133,172,229,143,184,46,233,155,134,229,155,162,229,174,162,230,136,183,233,131,168
If you are not seeing a UTF-8 character set then your issue may relate to the character set you are using to store the strings; you can try changing the column from a CHAR or VARCHAR2 data type to NCHAR or NVARCHAR2.
I want to match characters which start with
德州分公司.and end with公司.
The simplest method, if you do not need to filter the intervening characters is not to use regular expressions but to use LIKE:
SELECT *
FROM sf_group
WHERE group_name LIKE '德州分公司.%公司';
Which outputs:
GROUP_NAME 德州分公司.禹城分公司 德州分公司.齐河分公司
If you want to filter the intervening characters then your first query works:
SELECT '^德州分公司\.(['
|| unistr('\4e00')
|| '-'
|| unistr('\9fa5')
|| ']*)公司$' FROM DUAL;
But you can also hardcode the characters that match unistr('\4e00') and unistr('\9fa5'):
SELECT *
FROM sf_group
WHERE REGEXP_LIKE(group_name, '^德州分公司\.[一-龥]*公司$')
and they both output:
> | GROUP_NAME |
> | :------------------------------ |
> | 德州分公司.禹城分公司 |
> | 德州分公司.齐河分公司 |
If your query is not working and you want to find the values it is not working for then you can use:
SELECT group_name,
DUMP(
REGEXP_SUBSTR(t.group_name, '^德州分公司\.(.*)公司$', 1, 1, NULL, 1),
1016
) AS group_name_dump
FROM SF_GROUP T
WHERE -- Find the rows that match the start and end of the pattern.
regexp_like(t.group_name, '^德州分公司\.(.*)公司$')
AND -- Find the rows where the middle of the pattern does not match.
NOT REGEXP_LIKE(
-- Extract the middle capturing group
REGEXP_SUBSTR(t.group_name, '^德州分公司\.(.*)公司$', 1, 1, NULL, 1),
'^[' || unistr('\4e00') || '-' || unistr('\9fa5') || ']*$'
);
The query:
select *
FROM SF_GROUP T
where regexp_like(t.group_name,
'^德州分公司\.([\u4e00-\u9fa5]*)公司$');
Will not work because the Regular Expression Operator Multilingual Enhancements documentation states:
Oracle lets you enter multibyte characters directly, if you have a direct input method, or you can use functions to compose the multibyte characters. You cannot use the Unicode hexadecimal encoding value of the form '\xxxx'. Oracle evaluates the characters based on the byte values used to encode the character, not the graphical representation of the character. All accented characters are considered word characters.
So [\u4e00-\u9fa5] matches either the character \ or u oe 4 or e or 0 or the range 0-\ or u or 9 or f or a or 5.
db<>fiddle here
CodePudding user response:
As an addendum to @MTO's fine answer and your comment under the question:
But why ... did't work?
... when clearly it did work in the db<>fiddle MTO provided...
It's possible that your NLS session settings are affecting the outcome.
As noted in the documentatation, "the REGEXP_LIKE condition is collation-sensitive".
With binary collation the query returns the expected result, but it won't always with other settings. If you have NLS_COMP set to 'LINGUISTIC' and NLS_SORT set to 'SCHINESE_RADICAL_M' or 'SCHINESE_STROKE_M' then the query still does what you expect; but if you have NLS_SORT set to 'SCHINESE_PINYIN_M' then it won't return any data. That seems to be what you're seeing.
db<>fiddle based on MTO's, adding the same query repeated with those three settings - showing results for the first two and no results for 'SCHINESE_PINYIN_M'.
Read more about linguistic sorting in the documentation.
You can change your session settings, or switch to the .* approach to match any characters between the strings you specified, or use LIKE; as MTO also showed.