I am working with extremely high dimensional biological count data (single cell RNA sequencing where rows are cell ID and columns are genes).
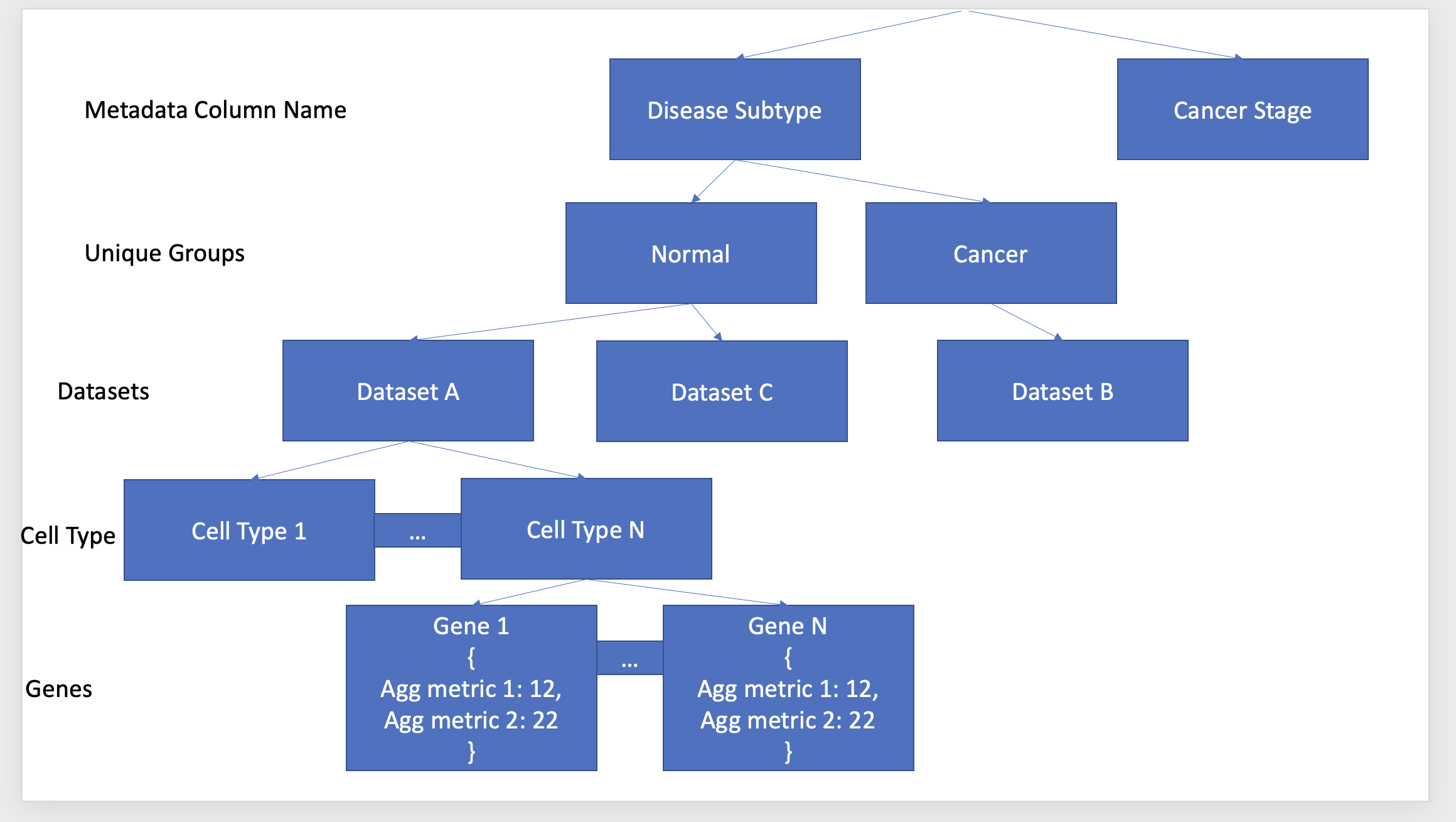
Each dataset is a separate flat file (AnnData format). Each flat file can be broken down by various metadata attributes, including by cell type (eg: muscle cell, heart cell), subtypes (eg: a lung dataset can be split into normal lung and cancerous lung), cancer stage (eg: stage 1, stage 2), etc.
The goal is to pre-compute aggregate metrics for a specific metadata column, sub-group, dataset, cell-type, gene combination and keep that readily accessible such that when a person queries my web app for a plot, I can quickly retrieve results (refer to Figure below to understand what I want to create). I have generated Python code to assemble the dictionary below and it has sped up how quickly I can create visualizations.
Only issue now is that the memory footprint of this dictionary is very high (there are ~10,000 genes per dataset). What is the best way to reduce the memory footprint of this dictionary? Or, should I consider another storage framework (briefly saw something called Redis Hashes)?
CodePudding user response:
One option to reduce your memory footprint but keep fast lookup is to use an hdf5 file as a database. This will be a single large file that lives on your disk instead of memory, but is structured the same way as your nested dictionaries and allows for rapid lookups by reading in only the data you need. Writing the file will be slow, but you only have to do it once and then upload to your web-app.
To test this idea, I've created two test nested dictionaries in the format of the diagram you shared. The small one has 1e5 metadata/group/dataset/celltype/gene entries, and the other is 10 times larger.
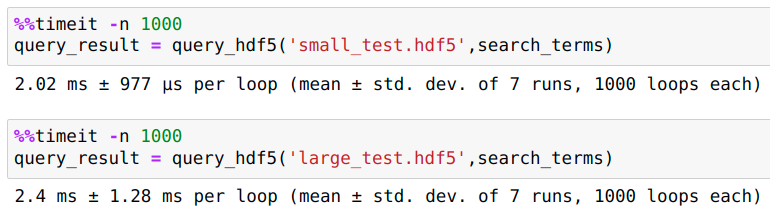
Writing the small dict to hdf5 took ~2 minutes and resulted in a file 140 MB in size while the larger dict-dataset took ~14 minutes to write to hdf5 and is a 1.4 GB file.
Querying the small and large hdf5 files similar amounts of time showing that the queries scale well to more data.
Here's the code I used to create the test dict-datasets, write to hdf5, and query
import h5py
import numpy as np
import time
def create_data_dict(level_counts):
"""
Create test data in the same nested-dict format as the diagram you show
The Agg_metric values are random floats between 0 and 1
(you shouldn't need this function since you already have real data in dict format)
"""
if not level_counts:
return {f'Agg_metric_{i 1}':np.random.random() for i in range(num_agg_metrics)}
level,num_groups = level_counts.popitem()
return {f'{level}_{i 1}':create_data_dict(level_counts.copy()) for i in range(num_groups)}
def write_dict_to_hdf5(hdf5_path,d):
"""
Write the nested dictionary to an HDF5 file to act as a database
only have to create this file once, but can then query it any number of times
(unless the data changes)
"""
def _recur_write(f,d):
for k,v in d.items():
#check if the next level is also a dict
sk,sv = v.popitem()
v[sk] = sv
if type(sv) == dict:
#this is a 'node', move on to next level
_recur_write(f.create_group(k),v)
else:
#this is a 'leaf', stop here
leaf = f.create_group(k)
for sk,sv in v.items():
leaf.attrs[sk] = sv
with h5py.File(hdf5_path,'w') as f:
_recur_write(f,d)
def query_hdf5(hdf5_path,search_terms):
"""
Query the hdf5_path with a list of search terms
The search terms must be in the order of the dict, and have a value at each level
Output is a dict of agg stats
"""
with h5py.File(hdf5_path,'r') as f:
k = '/'.join(search_terms)
try:
f = f[k]
except KeyError:
print('oh no! at least one of the search terms wasnt matched')
return {}
return dict(f.attrs)
################
# start #
################
#this "small_level_counts" results in an hdf5 file of size 140 MB (took < 2 minutes to make)
#all possible nested dictionaries are made,
#so there are 40*30*10*3*3 = ~1e5 metadata/group/dataset/celltype/gene entries
num_agg_metrics = 7
small_level_counts = {
'Gene':40,
'Cell_Type':30,
'Dataset':10,
'Unique_Group':3,
'Metadata':3,
}
#"large_level_counts" results in an hdf5 file of size 1.4 GB (took 14 mins to make)
#has 400*30*10*3*3 = ~1e6 metadata/group/dataset/celltype/gene combinations
num_agg_metrics = 7
large_level_counts = {
'Gene':400,
'Cell_Type':30,
'Dataset':10,
'Unique_Group':3,
'Metadata':3,
}
#Determine which test dataset to use
small_test = True
if small_test:
level_counts = small_level_counts
hdf5_path = 'small_test.hdf5'
else:
level_counts = large_level_counts
hdf5_path = 'large_test.hdf5'
np.random.seed(1)
start = time.time()
data_dict = create_data_dict(level_counts)
print('created dict in {:.2f} seconds'.format(time.time()-start))
start = time.time()
write_dict_to_hdf5(hdf5_path,data_dict)
print('wrote hdf5 in {:.2f} seconds'.format(time.time()-start))
#Search terms in order of most broad to least
search_terms = ['Metadata_1','Unique_Group_3','Dataset_8','Cell_Type_15','Gene_17']
start = time.time()
query_result = query_hdf5(hdf5_path,search_terms)
print('queried in {:.2f} seconds'.format(time.time()-start))
direct_result = data_dict['Metadata_1']['Unique_Group_3']['Dataset_8']['Cell_Type_15']['Gene_17']
print(query_result == direct_result)
CodePudding user response:
Although Python dictionaries themselves are fairly efficient in terms of memory usage you are likely storing multiple copies of the strings you are using as dictionary keys. From your description of your data structure it is likely that you have 10000 copies of “Agg metric 1”, “Agg metric 2”, etc for every gene in your dataset. It is likely that these duplicate strings are taking up a significant amount of memory. These can be deduplicated with sys.inten so that although you still have as many references to the string in your dictionary, they all point to a single copy in memory. You would only need to make a minimal adjustment to your code by simply changing the assessment to data[sys.intern(‘Agg metric 1’)] = value. I would do this for all of the keys used at all levels of your dictionary hierarchy.