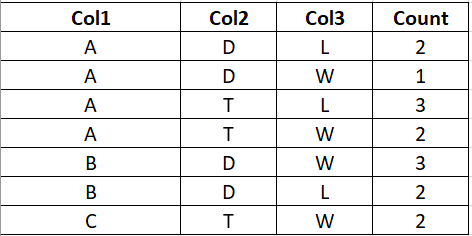
I have a df of the below format. Here the 'Count' column is the count of 'Col3'. Considering the first two rows, it has 2 counts of L and 1 count of W.
input_data = {
'Col1' : ['A','A','A','A','B','B','C'],
'Col2' : ['D','D','T','T','D','D','T'],
'Col3' : ['L','W','L','W','W','L','W'],
'Count': [2,1,3,2,3,2,2]
}
input_df = pd.DataFrame(input_data)
print(input_df)
I want to convert this df into the below format -required_df
output_data = {
'Col1' : ['A','A','B','C'],
'Col2' : ['D','T','D','T'],
'New_Col3' : ['L/W','L/W','L/W','W'],
'W_Count' : [1,3,3,2],
'L_Count' : [2,2,2,0]
}
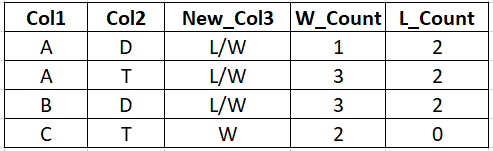
i.e, the first 2 rows of the first df is converted into the first row of the required_df. For each unique set of ['Col1','Col2'], values of 'Col3' is joined with '/' and the count is added as 2 new columns W-Count and L_Count. Variation in last row, where there is only W value.
I know we need to do groupby(['Col1','Col2']) but unable to think after that to get the values of other two columns as reflected in required_df. What would be the best way to achieve this?
As the real data is sensitive, I cannot share it here. But the original data is large with lakhs of rows.
CodePudding user response:
You can combine a groupby.agg and pivot_table:
(df
.groupby(['col1', 'col2'])
.agg(**{'New_col3': ('col3', lambda x: '/'.join(sorted(x)))})
.join(df.pivot_table(index=['col1', 'col2'],
columns='col3',
values='col4',
fill_value=0)
.add_suffix('_count')
)
.reset_index()
)
Output:
col1 col2 New_col3 L_count W_count
0 A D L/W 2 1
1 A T L/W 3 2
2 B D L/W 2 3
3 C T W 0 2
Used input:
df = pd.DataFrame({'col1': list('AAAABBC'),
'col2': list('DDTTDDT'),
'col3': list('LWLWWLW'),
'col4': (2,1,3,2,3,2,2)})