I apologize if this is a rudimentary question. I feel like it should be easy but I cannot figure it out. I have the code that is listed below that essentially looks at two columns in a CSV file and matches up job titles that have a similarity of 0.7. To do this, I use difflib.get_close_matches. However, the output is multiple single lines and whenever I try to convert to a DataFrame, every single line is its own DataFrame and I cannot figure out how to merge/concat them. All code, as well as current and desired outputs are below. Any help would be much appreciated.
Current Code is:
import pandas as pd
import difflib
df = pd.read_csv('name.csv')
aLists = list(df['JTs'])
bLists = list(df['JT'])
n=3
cutoff = 0.7
for aList in aLists:
best = difflib.get_close_matches(aList, bLists, n, cutoff)
print(best)
Current Output is:
['SW Engineer']
['Manu Engineer']
[]
['IT Help']
Desired Output is:
Output
0 SW Engineer
1 Manu Engineer
2 (blank)
3 IT Help
The table I am attempting to do this one is:
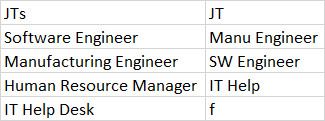
Any help would be greatly appreciated!
CodePudding user response:
Here is a simple way to achieve this.I have converted first to a string.Then the first and last brackets are removed from that string and then is appended to a global list.
import pandas as pd
import difflib
import numpy as np
df = pd.read_csv('name.csv')
aLists = list(df['JTs'])
bLists = list(df['JT'])
n = 3
cutoff = 0.7
best = []
for aList in aLists:
temp = difflib.get_close_matches(aList, bLists, n, cutoff)
temp = str(temp)
strippedString = temp.lstrip("[").rstrip("]")
# print(temp)
best.append(strippedString)
print(best)
Output
[
"'SW Engineer'",
"'Manu Engineer'",
'',
"'IT Help'"
]
Here is another better way to achieve this. You can simply use numpy to concatenate multiple arrays into single one.And then you can convert it to normal array if you want.
import pandas as pd
import difflib
import numpy as np
df = pd.read_csv('name.csv')
aLists = list(df['JTs'])
bLists = list(df['JT'])
n = 3
cutoff = 0.7
best = []
for aList in aLists:
temp = difflib.get_close_matches(aList, bLists, n, cutoff)
best.append(temp)
# print(best)
# Use concatenate() to join two arrays
combinedNumpyArray = np.concatenate(best)
#Converting numpy array to normal array
normalArray = combinedNumpyArray.tolist()
print(normalArray)
Output
['SW Engineer', 'Manu Engineer', 'IT Help']
Thanks
CodePudding user response:
You could use Panda's .apply() to run your function on each entry. This could then either be added as a new column or a new dataframe created.
For example:
import pandas as pd
import difflib
def get_best_match(word):
matches = difflib.get_close_matches(word, JT, n, cutoff)
return matches[0] if matches else None
df = pd.read_csv('name.csv')
JT = df['JT']
n = 3
cutoff = 0.7
df['Output'] = df['JTs'].apply(get_best_match)
Or for a new dataframe:
df_output = pd.DataFrame({'Output' : df['JTs'].apply(get_best_match)})
Giving you:
JTs JT Output
0 Software Engineer Manu Engineer SW Engineer
1 Manufacturing Engineer SW Engineer Manu Engineer
2 Human Resource Manager IT Help None
3 IT Help Desk f IT Help
Or:
Output
0 SW Engineer
1 Manu Engineer
2 None
3 IT Help