After trying suggestion, I want to get "title" in the follwing "li" tag
{kind=link}
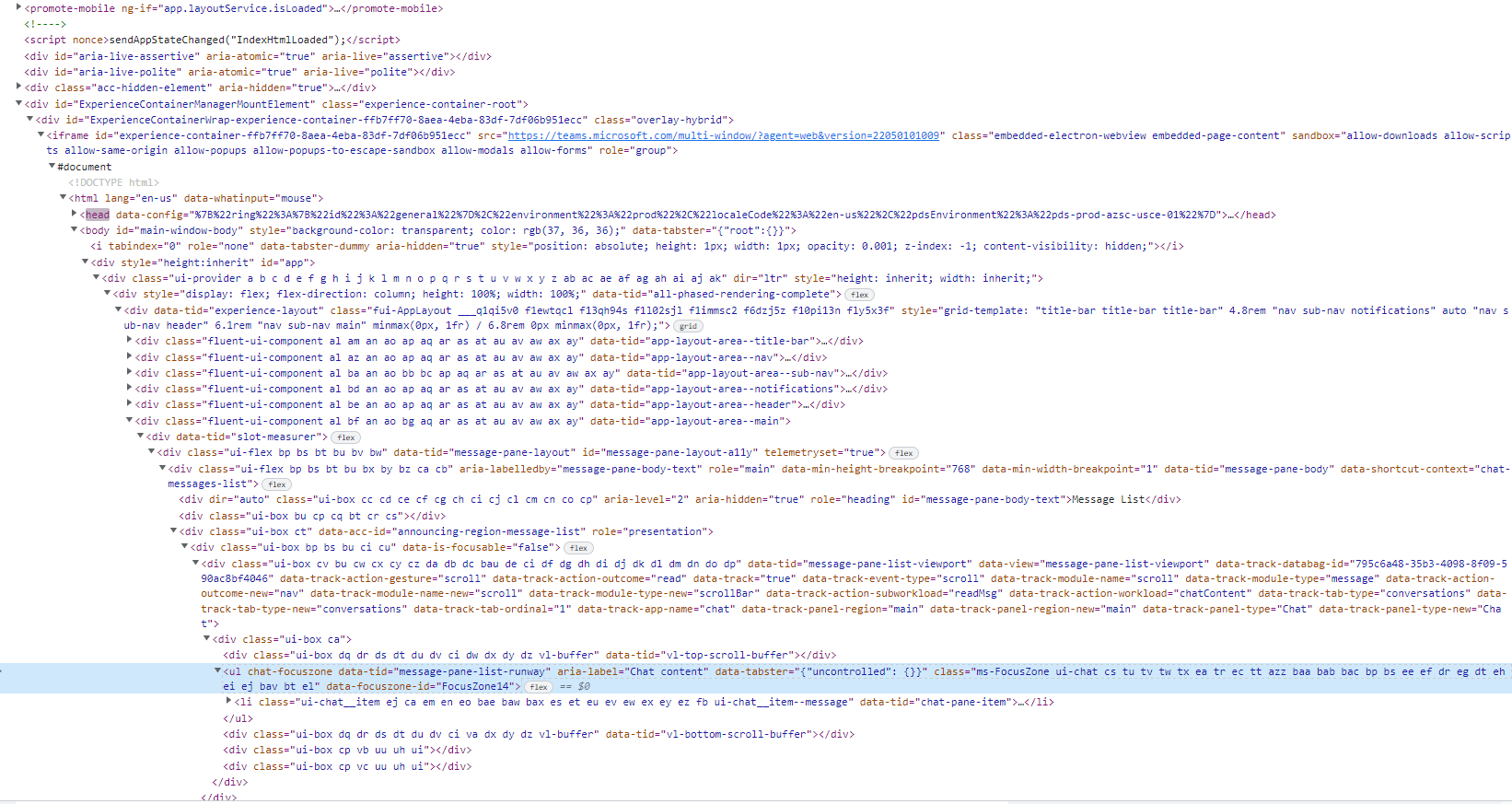
I'm trying to extract the following "ul" element from a webpage using selenium. Using Python, I can't figure out what the X_PATH should be, I've tried everything I could think of. Also tried the css_selection. I'm getting back nothing.
I want to iterate over the "li" elements within that specific "ul" element. If anybody could help it would be appreciated, I've literally tried everything I can think/search.
CodePudding user response:
Check is that element are inside some iFrame, maybe is for that, if that dont work install selenium extension in your browser and try to recreat the flow, you will receive all xpath, is a way that I use when nothing is working to me.
CodePudding user response:
//ul[@aria-label='Chat content']/li[1]/div[1]/div[1]
To me it looks like you could just grab the ul by it's aria label and then select the first li from there. You could also just inspect the element and copy the xpath from the developers console.
It also seems to be in an iframe.
wait = WebDriverWait(driver, 30)
wait.until(EC.frame_to_be_available_and_switch_to_it((By.XPATH, "//iframe[@class='embedded-electron-webview embedded-page-content']")))
Imports:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC