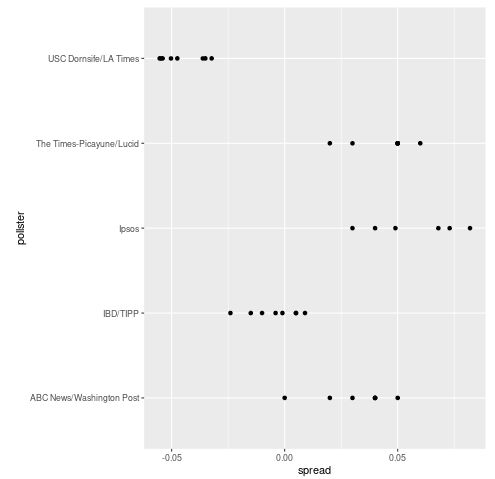
I want to choose only the top five options in a scatterplot. Here's the code:
library(dslabs)
data(polls_us_election_2016)
polls <- polls_us_election_2016 %>%
filter(state == "U.S." & enddate >= "2016-10-31" &
(grade %in% c("A ","A","A-","B ") | is.na(grade)))
polls <- polls %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100)
d_hat <- polls %>%
summarize(d_hat = sum(spread * samplesize) / sum(samplesize)) %>%
pull(d_hat)
p_hat <- (d_hat 1)/2
moe <- 1.96 * 2 * sqrt(p_hat * (1 - p_hat) / sum(polls$samplesize))
polls %>% ggplot(aes(spread, pollster))
geom_point(color="black", binwidth = .01)
This is the output graph:
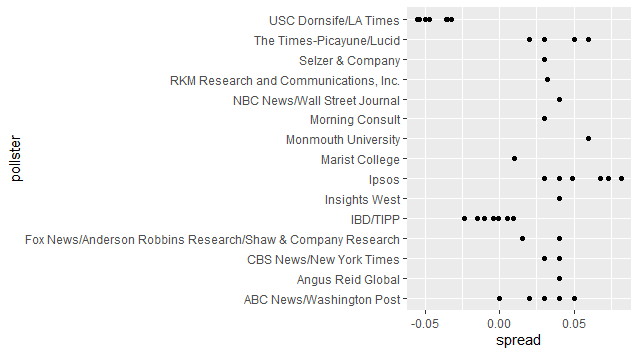
The following is the desired graph:
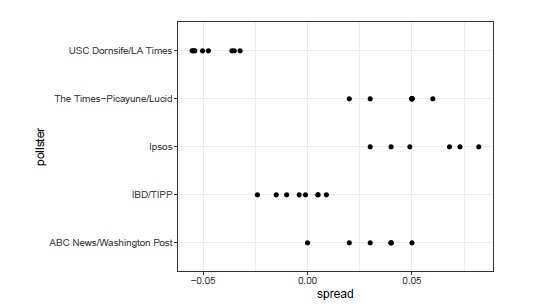
CodePudding user response:
The pipe nest %>% head(5) %>% unnest gives you the first 5 groups of rows in the order they occur in the data frame. Then, ggplot2 will sort them in an alpha lexical way:
library(dslabs)
library(tidyverse)
data(polls_us_election_2016)
polls <- polls_us_election_2016 %>%
filter(state == "U.S." & enddate >= "2016-10-31" &
(grade %in% c("A ","A","A-","B ") | is.na(grade)))
polls <- polls %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100)
d_hat <- polls %>%
summarize(d_hat = sum(spread * samplesize) / sum(samplesize)) %>%
pull(d_hat)
p_hat <- (d_hat 1)/2
moe <- 1.96 * 2 * sqrt(p_hat * (1 - p_hat) / sum(polls$samplesize))
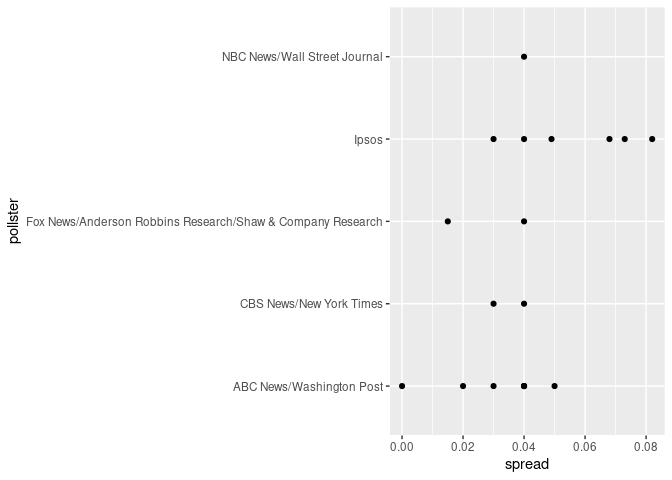
polls %>%
nest(-pollster) %>%
head(5) %>%
unnest(data) %>%
ggplot(aes(spread, pollster))
geom_point(color="black", binwidth = .01)
#> Warning: All elements of `...` must be named.
#> Did you want `data = -pollster`?
#> Warning: Ignoring unknown parameters: binwidth
Created on 2022-06-21 by the