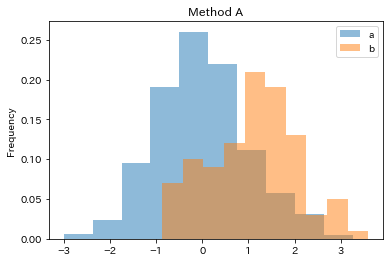
Plotting multiple relative frequencies (sum of bin to be one, not area of bin to be one) was not easier than I thought.
In Method A, We can use weights argument and plotted properly, but it is not intuitive.
import numpy as np
import pandas as pd
df_a = pd.DataFrame(np.random.randn(1000),columns=['a'])
df_b = pd.DataFrame(1 np.random.randn(100),columns=['b'])
# Method A
ax = df_a.plot(kind='hist', weights= np.ones_like(df_a) / len(df_a),alpha=0.5)
df_b.plot(kind='hist', weights= np.ones_like(df_b) / len(df_b),alpha=0.5 ,ax= ax )
plt.title("Method A")
plt.show()
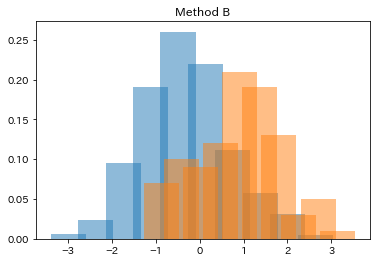
In Method B, the part for determining relative frequencies count_a/sum(count_a) is easy to understand, but the diagram is not beautiful.
# Method B
count_a,bins_a = np.histogram(df_a.a)
count_b,bins_b = np.histogram(df_b.b)
plt.bar(bins_a[:-1],count_a/sum(count_a),alpha=0.5 )
plt.bar(bins_b[:-1],count_b/sum(count_b),alpha=0.5 )
plt.title("Method B")
Is there another way to get a graph directly from the data without doing the calculations myself?
CodePudding user response:
The problem with your bar plot is that the width is fixed by default to 0.8. This can easily be adjusted to account for the real width of your histogram:
plt.bar(bins_a[:-1], count_a/sum(count_a), width = bins_a[1:] - bins_a[:-1], alpha = 0.5, align = 'edge')
and this is the result:
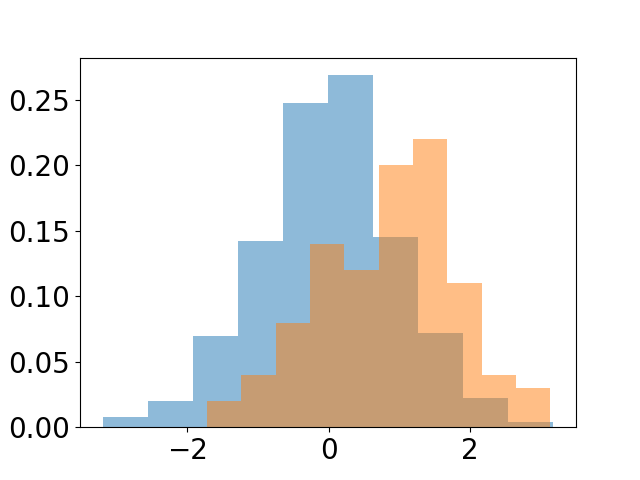
In this example the bin width is fixed but by providing a sequence you have a more flexible option, which can be used also in the case of variable bin sizes.
A different option is to use seaborn as suggested in the comment:
import seaborn as sns
df_hist = pd.concat([df_a, df_b]).melt()
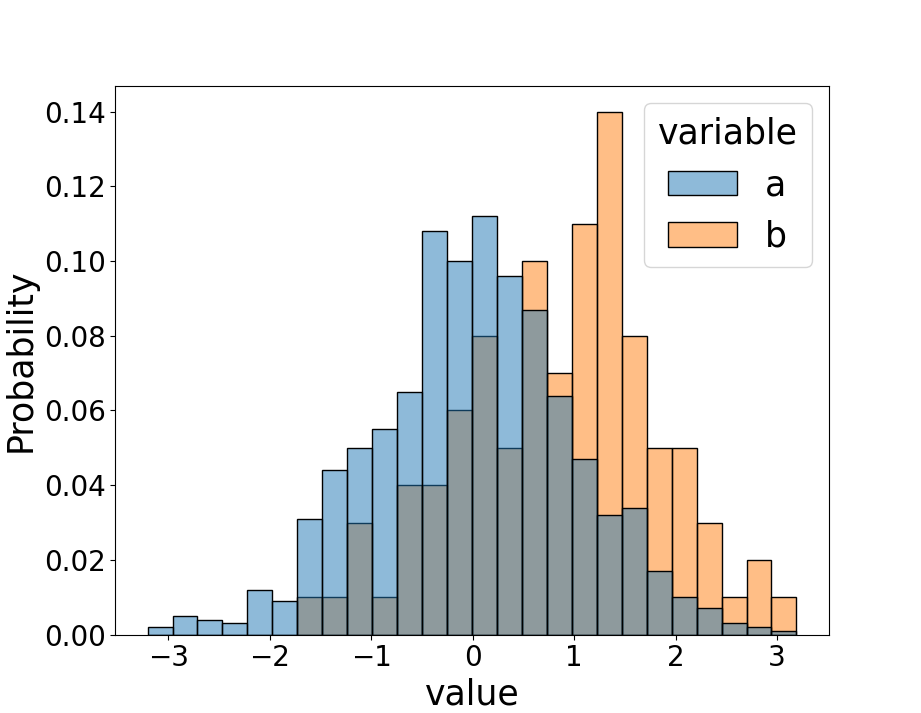
sns.histplot(data = df_hist, x = 'value', hue = 'variable', stat = 'probability', common_norm = False)