How can I filter in R only those rows in data.frame in which the value for column V6 appears exactly 2 times.
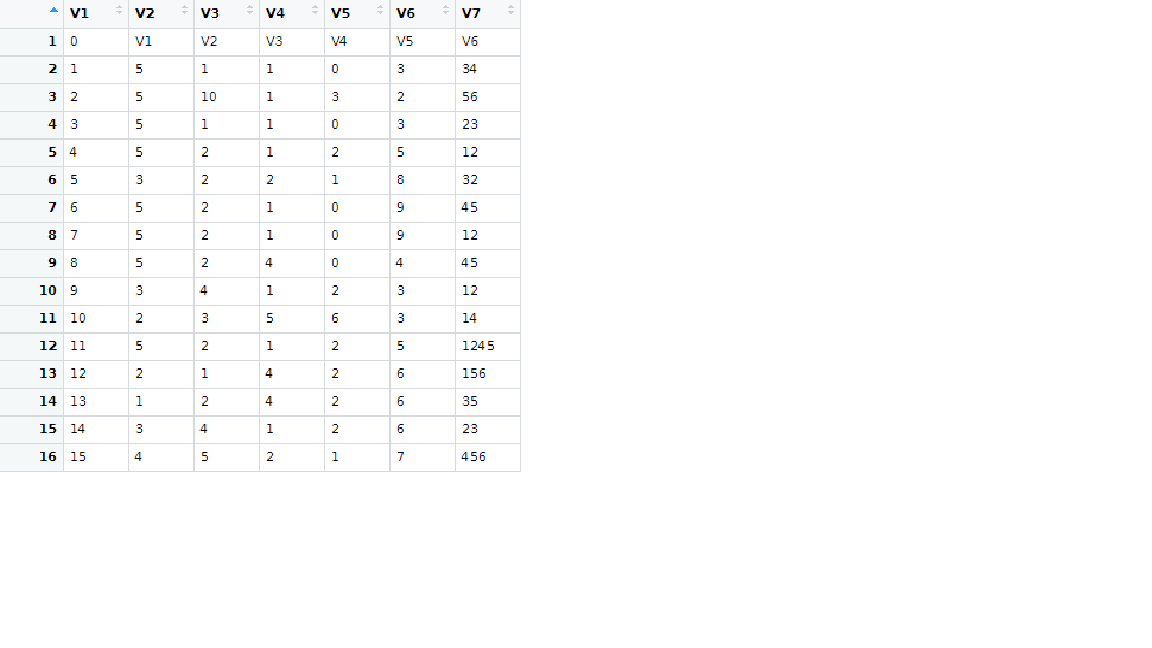
I try:
library(dplyr)
df <- as.data.frame(date)
df1 <- subset(df,duplicated(V6))
CodePudding user response:
You can use the following code:
df[with(df, ave(V6, V6, FUN = length)) == 2,]
Output:
V1 V6
5 4 5
7 6 9
8 7 9
12 11 5
Data used:
df <- data.frame(V1 = c(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15),
V6 = c("V5", "3", "2", "3", "5", "8", "9", "9", "4", "3", "3", "5", "6", "6", "6", "7"))
CodePudding user response:
Something like this? Values 3 and 4 only appear once in V6, value 5 three times. So only rows having value of 1 in V6 were kept:
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
data <- tibble(
V1 = c(1,2,3,4,5,6,7),
V6 = c(1,1,3,4,5,5,5)
)
data
#> # A tibble: 7 × 2
#> V1 V6
#> <dbl> <dbl>
#> 1 1 1
#> 2 2 1
#> 3 3 3
#> 4 4 4
#> 5 5 5
#> 6 6 5
#> 7 7 5
data %>%
group_by(V6) %>%
filter(n() == 2)
#> # A tibble: 2 × 2
#> # Groups: V6 [1]
#> V1 V6
#> <dbl> <dbl>
#> 1 1 1
#> 2 2 1
Created on 2022-06-24 by the reprex package (v2.0.0)