I am trying to convert a (.csv) file to a .json file which is stored in the form of a column array.
The input (.csv) file is:
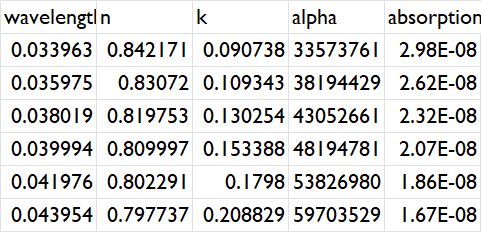
This is my desired result:
{
"wavelength":[0.033962528,0.035974933,0.03801894,0.039994474,0.041975898,0.043954162],
"n":[0.842171,0.83072,0.819753,0.809997,0.802291,0.797737],
"k":[0.090738197,0.10934279,0.13025372,0.15338756,0.17980019,0.20882868],
"alpha":[33573761.42,38194428.97,43052660.58,48194781.27,53826980.05,59703529.05],
"absorption_length":[2.98e-8,2.62e-8,2.32e-8,2.07e-8,1.86e-8,1.67e-8]
}
I am using this script:
import csv
import json
with open('test.csv') as infile:
reader = csv.DictReader(infile)
out = [{"wavelength": row['wavelength'],"n": row["n"], "k": row["k"],, "alpha": ["alpha"]} for row in reader]
with open('data.json', 'w') as outfile:
json.dump(out, outfile)
But I am getting the following:
[{"wavelength": "0.033962528", "n": "0.842171", "k": "0.090738197", "alpha": ["alpha"]},
{"wavelength": "0.035974933", "n": "0.83072", "k": "0.10934279", "alpha": ["alpha"]},
{"wavelength": "0.03801894", "n": "0.819753", "k": "0.13025372", "alpha": ["alpha"]},
{"wavelength": "0.039994474", "n": "0.809997", "k": "0.15338756", "alpha": ["alpha"]},
{"wavelength": "0.041975898", "n": "0.802291", "k": "0.17980019", "alpha": ["alpha"]},
{"wavelength": "0.043954162", "n": "0.797737", "k": "0.20882868", "alpha": ["alpha"]}]
I am trying to get the desired result.
CodePudding user response:
Since you tagged pandas, this is very easy:
df = pd.read_csv(filename, ...)
result_dict = df.to_dict(orient='list')
You can now json.dump this dict to a file, assuming that's the end goal.
CodePudding user response:
You can do it this way
import csv
import json
with open('test.csv') as infile:
reader = csv.DictReader(infile)
out = [{"wavelength": row['wavelength'],"n": row["n"], "k": row["k"], "alpha": ["alpha"]} for row in reader]
keys = out[0].keys()
ref_out = {key: [i[key] for i in out ] for key in keys}
with open('data.json', 'w') as outfile:
json.dump(ref_out, outfile)
CodePudding user response:
You can do this in a nested list comprehension inside a dictionary comprehension like this:
with open('test.csv') as infile:
reader = csv.DictReader(infile)
data = list(reader)
out = {key: [row[key] for row in data] for key in reader.fieldnames}
I did convert the data to a list because if you use for row in reader directly in the dictionary comprehension the reader gets consumed for the first key and the other ones will be empty. This may not be optimal if you have a lot of data.