import scrapy
from scrapy.http import Request
from scrapy.crawler import CrawlerProcess
class TestSpider(scrapy.Spider):
name = 'test'
start_urls = ['https://rejestradwokatow.pl/adwokat/list/strona/1/sta/2,3,9']
custom_settings = {
'CONCURRENT_REQUESTS_PER_DOMAIN': 1,
'DOWNLOAD_DELAY': 1,
'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
def parse(self, response):
books = response.xpath("//td[@class='icon_link']//a//@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
wev={}
d1=response.xpath("//*[@class='line_list_K']//div//span")
for i in range(len(d1)):
if 'Status:' in d1[i].get():
d2=response.xpath("//div[" str(i 1) "]//text()").get()
print(d2)
I will get the status value but they will give me empty output this is page link 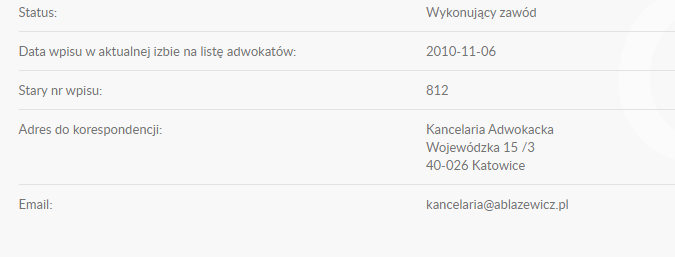
CodePudding user response:
Why not selecting your element more specific by its text and getting the text from its next sibling:
//span[text()[contains(.,'Status')]]/following-sibling::div/text()
Example: http://xpather.com/ZUWI58a4
To get the email:
//span[text()[contains(.,'Email')]]/following-sibling::div/(concat(@data-ea,'@',@data-eb))
CodePudding user response:
Your d2 xpath isn't targeting the correct div.
This should work:
def parse_book(self, response):
wev = {} # <- this is never used
for child in response.xpath('//div[@]/*'):
if 'Status:' child.xpath(".//span/text()").get():
d2 = child.xpath(".//div/text()").get()
print(d2)