I want something like this:
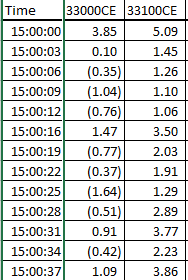
Time 33000CE 33100CE
15:00:00 3.85 5.09
15:00:03 0.10 1.45
15:00:06 (0.35) 1.26
15:00:09 (1.04) 1.10
15:00:12 (0.76) 1.06
15:00:16 1.47 3.50
15:00:19 (0.77) 2.03
15:00:22 (0.37) 1.91
15:00:25 (1.64) 1.29
15:00:28 (0.51) 2.89
15:00:31 0.91 3.77
and I have various dataframes of the form like (ignore other column names for now, but timestamp column is common in all dataframes):
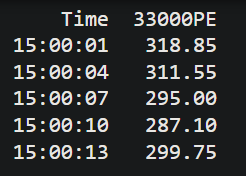
Time 32600PE
15:00:01 12.35
15:00:04 11.30
15:00:07 9.20
15:00:10 8.35
15:00:13 9.95
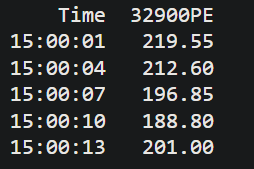
Time 32500PE
15:00:01 3.70
15:00:04 3.50
15:00:07 3.15
15:00:10 3.05
15:00:13 3.65
and when i am using concat function:
dfList = [df1, df2]
new_df = pd.concat(dfList)
i am getting something like this:
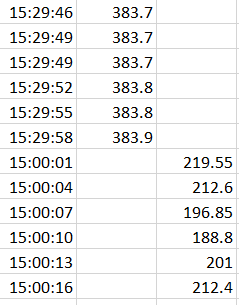
How can i get to my desired result to have rows merged on the time column and not having separate rows for each timestamp?
CodePudding user response:
You can merge your dataframes on Time:
import pandas as pd
df1 = pd.DataFrame({
'Time': {0: '15:00:01',
1: '15:00:04',
2: '15:00:07',
3: '15:00:10',
4: '15:00:13'},
'32600PE': {0: 12.35, 1: 11.3, 2: 9.2, 3: 8.35, 4: 9.95}}
)
df2 = pd.DataFrame({
'Time': {0: '15:00:01',
1: '15:00:04',
2: '15:00:07',
3: '15:00:10',
4: '15:00:13'},
'32500PE': {0: 3.7, 1: 3.5, 2: 3.15, 3: 3.05, 4: 3.65}}
)
print(df1.merge(df2, on='Time', how='outer'))
Output:
Time 32600PE 32500PE
0 15:00:01 12.35 3.70
1 15:00:04 11.30 3.50
2 15:00:07 9.20 3.15
3 15:00:10 8.35 3.05
4 15:00:13 9.95 3.65
Edit: specifying how='outer' to get all timestamps
CodePudding user response:
Here is your solution using concat. We are joining the two dataframe on common index.
Creating data
# first data frame
d1 = {
'Time' : ['15:00:01', '15:00:04', '15:00:07', '15:00:10', '15:00:13'],
'32600PE' : ['12.35', '11.30', '9.20', '8.35', '9.95']
}
df1 = pd.DataFrame(data=d1)
# second data frame
d2 = {
'Time' : ['15:00:01', '15:00:04', '15:00:07', '15:00:10', '15:00:13'],
'32500PE' : ['3.70', '3.50', '3.15', '3.05', '3.65']
}
df2 = pd.DataFrame(data=d2)
Concat
df = pd.concat([df1.set_index('Time'), df2.set_index('Time')], axis=1)
Output :
32600PE 32500PE
Time
15:00:01 12.35 3.70
15:00:04 11.30 3.50
15:00:07 9.20 3.15
15:00:10 8.35 3.05
15:00:13 9.95 3.65
You can reset the index and convert Time back to column
df = pd.concat([df1.set_index('Time'), df2.set_index('Time')], axis=1).reset_index()
Output :
Time 32600PE 32500PE
0 15:00:01 12.35 3.70
1 15:00:04 11.30 3.50
2 15:00:07 9.20 3.15
3 15:00:10 8.35 3.05
4 15:00:13 9.95 3.65
EDIT :
@Tranbi's solution won't give you all the data in case if there is a time stamp value that is not present in df1 or df2. However concat will take care of that thing and will give NaN value for the timestamp value that is not present in other dataframe.
eg : Lets say df1 contains an extra value :
df1 = pd.DataFrame({
'Time': {0: '15:00:01',
1: '15:00:04',
2: '15:00:07',
3: '15:00:10',
4: '15:00:13',
5: '15:00:15'},
'32600PE': {0: 12.35, 1: 11.3, 2: 9.2, 3: 8.35, 4: 9.95, 5: 10.00}}
)
print(df1.merge(df2, on='Time'))
Output misses the extra row :
Time 32600PE 32500PE
0 15:00:01 12.35 3.70
1 15:00:04 11.30 3.50
2 15:00:07 9.20 3.15
3 15:00:10 8.35 3.05
4 15:00:13 9.95 3.65
My solution using concat gives you
Time 32600PE 32500PE
15:00:01 12.35 3.70
15:00:04 11.30 3.50
15:00:07 9.20 3.15
15:00:10 8.35 3.05
15:00:13 9.95 3.65
15:00:15 10.00 NaN
concat will also take care in case the timestamp values are jumbled in the dataframes
EDIT2 :
As @Tranbi stated, specifying the kwarg how='outer' fixes the issue