Python 3.6, Pandas 1.1.5 on windows 10
Trying to optimize the below for better performance on large dataset.
Purpose: randomly select a single value if the data contains several values separated by a space.
For example, from:
col1 col2 col3
0 a a b c a c
1 a b c a
2 a b c b b
to:
col1 col2 col3
0 a b c
1 a c a
2 b b b
So far:
df = pd.DataFrame({'col1': ['a', 'a b', 'a b c'],
'col2':['a b c', 'c', 'b'],
'col3':['a c', 'a', 'b'], })
# make data into a flat np.array
vals = list(itertools.chain.from_iterable(df.values))
vals_ = []
# randomly select a single value from each data point
for v in vals:
v = v.split(' ')
a = np.random.choice(len(v), 1)[0]
v = v[a]
vals_.append(v)
gf = pd.DataFrame(np.array(vals_).reshape(df.shape),
index = df.index,
columns =df.columns)
This is not fast on a large dataset. Any lead will be appreciated.
CodePudding user response:
Defining a function and applying it to the entire Pandas dataframe via
The function could be implemented via
def rndVal(x:str):
if len(x) > 1:
x = x.split(' ')
a = np.random.choice(len(x), 1)[0]
return x[a]
else:
return x
and is applicable with
df.applymap(rndVal)
returning
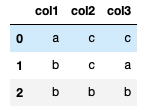
Regarding Performance. Running your attempt and applymap on a dataframe with 300,000 rows requires the former 18.6 s while this solution only takes 8.4 s.
CodePudding user response:
Pandas fast approach
Stack to reshape then split and explode the strings then groupby on multiindex and draw a sample of size 1 per group, then unstack back to reshape
(
df.stack().str.split().explode()
.groupby(level=[0, 1]).sample(1).unstack()
)
col1 col2 col3
0 a a c
1 b c a
2 a b b