sharing the sample file screenshots, script I developed and other details below.
In the countries_source.csv file, I have a list of countries and I need a subset of its data created in mycountries.csv file until I hit the value "Asia" in the first column.
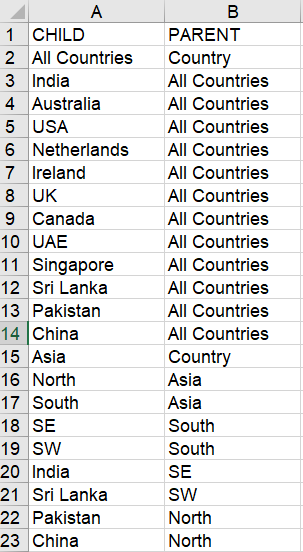
Using the below script, I was able to get the data till the 14th row - which is good. However, I need help with the below.
In the countries_source.csv file, I should get 17 to 21 rows as well based on the values in columns A and B - that is, every row that is a descendant of "South" (row 17) should be included in the mycountries.csv file as well. Other rows should be ignored.
import csv
import os
os.remove("C:/Users/Documents/Python Scripts/mycountries.csv")
with open("C:/Users/Documents/Python Scripts/countries_source.csv", "r") as source:
csv_reader = csv.reader(source)
lst=[]
with open("C:/Users/Documents/Python Scripts/mycountries.csv", "w",newline='') as result:
writer = csv.writer(result)
#print(lst)
for r in csv_reader:
lst.append(r)
for ele in lst:
if ele[0] != "Asia" :
writer.writerow(ele)
elif ele[0] == "Asia":
break
Based on the data in countries_source.csv file and my requirement as discussed above, the expected result of mycountries.csv file screenshot is provided below.
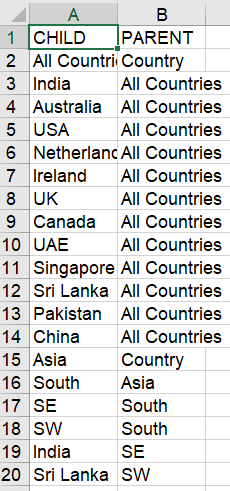
Could you please help me with some ideas? - I'm new to coding, please excuse any obvious mistakes in the code. Thank you!
CodePudding user response:
Create a boolean variable
check = True
And a List of south and its descendants
descendant = ["South"]
And replace your If and Elif with this
check = True
descendant = ["South"]
for ele in lst:
if check:
writer.writerow(ele)
if ele[0] == "Asia":
check = False
if ele[1] in descendants:
writer.writerow(ele)
descendant.append(ele[0])