I have this
| ID | Product |
|---|---|
| 001 | A |
| 001 | B |
| 001 | C |
| 002 | A |
| 002 | A |
| 002 | D |
| 003 | G |
| 003 | D |
| 003 | C |
| 004 | G |
| 004 | D |
| 004 | R |
and I wand ID list if they don't have product C...so:
002
CodePudding user response:
Consider below query:
SELECT DISTINCT ID FROM (
SELECT *, COUNTIF(product = 'C') OVER (PARTITION BY ID) AS cnt_C
FROM sample_table
) WHERE cnt_C = 0
output:
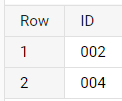
CodePudding user response:
There are multiple ways of doing this, but I think a very readable way is to use NOT EXISTS.
SELECT DISTINCT id
FROM mytable t1
WHERE NOT EXISTS (SELECT 1 FROM mytable t2 WHERE t2.id = t1.id AND t2.Product = 'C')
The WHERE clause checks that there is no row with product C and the same id. The DISTINCT ensures you don't get multiples of the same id returned.
CodePudding user response:
You can apply the set difference between all ids and all ids with a "c" with the standard way of doing it: using the NOT IN operator in the WHERE clause.
SELECT DISTINCT ID
FROM tab
WHERE id NOT IN (SELECT ID FROM tab WHERE Product = 'C')
CodePudding user response:
I am not sure but I think you just need a normal where
SELECT * FROM table_name WHERE product != product_name
*insert the table name in the place of Table_name and product name in the place of product_name
CodePudding user response:
select distinct
id
from
your_table_name
where
product <> 'C';
This will return you list of ID's that don't have product C