I have the following Pivot table:
| Subclass | Subclass2 | Layer | Amount |
|---|---|---|---|
| A | B | C | 5 |
| E | F | G | 100 |
I want to merge the 3 columns together and have Amount stay separate to form this:
| Col1 | Amount |
|---|---|
| A | NaN |
| B | NaN |
| C | 5 |
| E | NaN |
| F | NaN |
| G | 100 |
So Far I've turned it into a regular DataFrame and did this:
df.melt(id_vars = ['SubClass', 'SubClass2'], value_name = 'CQ')
But that didn't arrange it right at all. It messed up all the columns.
I've thought once I get the melt right, I could just change the NaN values to 0 or blanks.
EDIT
I need to keep Subclass & Subclass2 in the final column as they're the higher level mapping of Layer, hence why I want the output Col1 to include them before listing Layer with Amount next to it.
Thanks!
CodePudding user response:
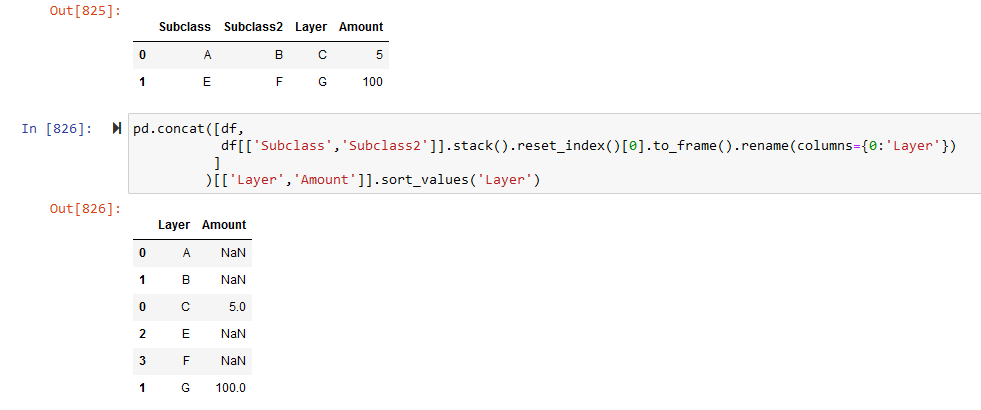
here is one way to do it
pd.concat([df,
df[['Subclass','Subclass2']].stack().reset_index()[0].to_frame().rename(columns={0:'Layer'})
]
)[['Layer','Amount']].sort_values('Layer')
Layer Amount
0 A NaN
1 B NaN
0 C 5.0
2 E NaN
3 F NaN
1 G 100.0
CodePudding user response:
Here is my interpretation. Using a stack instead of melt to preserve the order.
out = (df
.set_index('Amount')
.stack().reset_index(name='Col1')
.assign(Amount=lambda d: d['Amount'].where(d['level_1'].eq('Layer'), 0))
.drop(columns='level_1')
)
NB. with melt the syntax would be df.melt(id_vars='Amount', value_name='Col1'), and using variable in place of level_1
Output:
Amount Col1
0 0 A
1 0 B
2 5 C
3 0 E
4 0 F
5 100 G