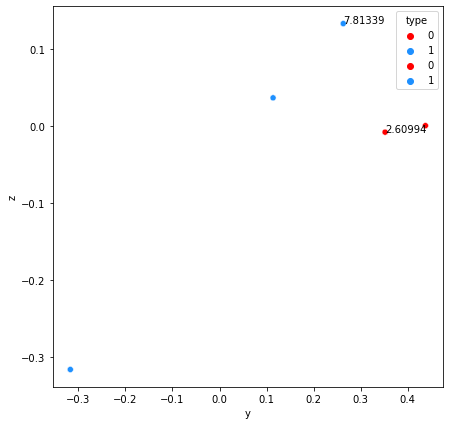
I have two dataset in csv format:
df2
type prediction 100000 155000
0 0 2.60994 3.40305
1 1 10.82100 34.68900
0 0 4.29470 3.74023
0 0 7.81339 9.92839
0 0 28.37480 33.58000
df
TIMESTEP id type y z v_acc
100000 8054 1 -0.317192 -0.315662 15.54430
100000 669 0 0.352031 -0.008087 2.60994
100000 520 0 0.437786 0.000325 5.28670
100000 2303 1 0.263105 0.132615 7.81339
105000 8055 1 0.113863 0.036407 5.94311
I am trying to match value of df2[100000] to df1[v_acc]. If value matched, I am making scatter plot from df with columns y and z. After that I want to to annoted scatter point with matched value.
What I want is:
(I want all annotaions in a same plot).
I tried to code in python for such condition but I am not getting all annotation points in a single plot instead I am getting multi plots with a single annotation. I am also getting this error:
189 if len(self) == 1:
190 return converter(self.iloc[0])
--> 191 raise TypeError(f"cannot convert the series to {converter}")
TypeError: cannot convert the series to <class 'float'>
Can I get some help to make a plot as I want?
Thank you. My code is here:
df2 = pd.read_csv('./result.csv')
print(df2.columns)
#print(df2.head(10))
df = pd.read_csv('./main.csv')
df = df[df['TIMESTEP'] == 100000]
for i in df['v_acc']:
for j in df2['100000']:
# sometimes numbers are long and different after decimals.So mathing 0.2f only
if "{0:0.2f}".format(i) == "{0:0.2f}".format(j):
plt.figure(figsize = (10,8))
sns.scatterplot(data = df, x = "y", y = "z", hue = "type", palette=['red','dodgerblue'], legend='full')
plt.annotate(i, (df['y'][df['v_acc'] == i], df['z'][df['v_acc'] == i]))
plt.grid(False)
plt.show()
break
CodePudding user response:
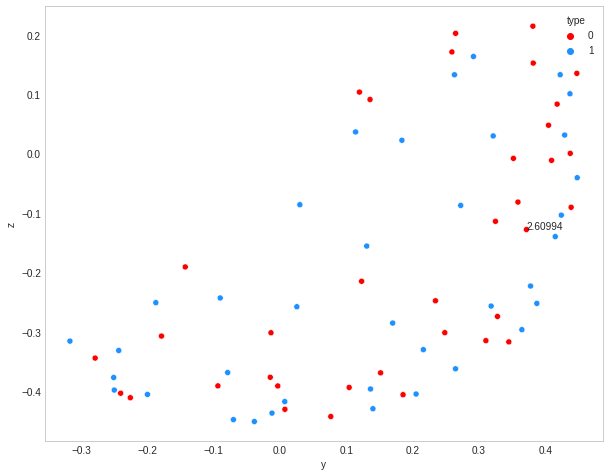
the reason for the multiple plots is because are you using plt.figure() inside the loop. This will create a single figure for each loop. You need to create that outside and only the individual scatter and annotate within the loop. Here is the updated code that ran for the data you provided. Other than that, think your code is fine...
fig, ax=plt.subplots(figsize = (7,7)) ### Keep this before the loop and call it as subplot
for i in df['v_acc']:
for j in df2[100000]:
# sometimes numbers are long and different after decimals.So mathing 0.2f only
if "{0:0.2f}".format(i) == "{0:0.2f}".format(j):
#plt.figure(figsize = (10,8))
ax=sns.scatterplot(data = df, x = "y", y = "z", hue = "type", palette=['red','dodgerblue'], legend='full')
ax.annotate(i, (df['y'][df['v_acc'] == i], df['z'][df['v_acc'] == i]))
break
plt.grid(False) ### Keep these two after the loop, just one show for one plot
plt.show()
Output plot