I have the following df:
df = pd.DataFrame({'from':['A','A','A','B','B','C','C','C'],'to':['J','C','F','C','M','Q','C','J'],'amount':[1,1,2,12,13,5,5,1]})
df
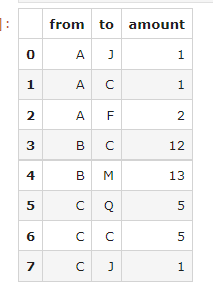
and I wish to sort it is such way that the highest amount of 'from' is first. So in this example, 'from' B has 12 13 = 25 so B is the first in the list. Then comes C with 11 and then A with 4.
One way to do it is like this:
df['temp'] = df.groupby(['from'])['amount'].transform('sum')
df.sort_values(by=['temp'], ascending =False)
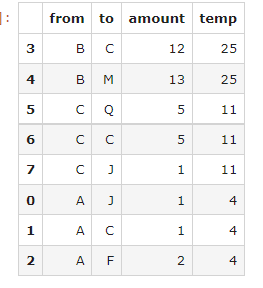
but I'm just adding another column. Wonder if there's a better way?
CodePudding user response:
I think your method is good and explicit.
A variant without the temporary column could be:
df.sort_values(by='from', ascending=False,
key=lambda x: df['amount'].groupby(x).transform('sum'))
output:
from to amount
3 B C 12
4 B M 13
5 C Q 5
6 C C 5
7 C J 1
0 A J 1
1 A C 1
2 A F 2
CodePudding user response:
In your case do with argsort
out = df.iloc[(-df.groupby(['from'])['amount'].transform('sum')).argsort()]
Out[53]:
from to amount
3 B C 12
4 B M 13
5 C Q 5
6 C C 5
7 C J 1
0 A J 1
1 A C 1
2 A F 2