1
i have just started using Pandas and i'm amazed by how flexible it is but i've hit a roadblock and need some help
I have a Data frame Df:
| Contract | Year | Val1 | Val2 | Val3 |
| A | 2020 | 90 | 95. | 100 |
|A | 2019 | 80 | 85.| 90|
|A | 2018 | 75. | 70. | 80 |
| B |2020 | 90. | 95. | 100 |
| B | 2019| 80 | 85.| 90 |
| B |2018 | 75. | 70. | 80 |
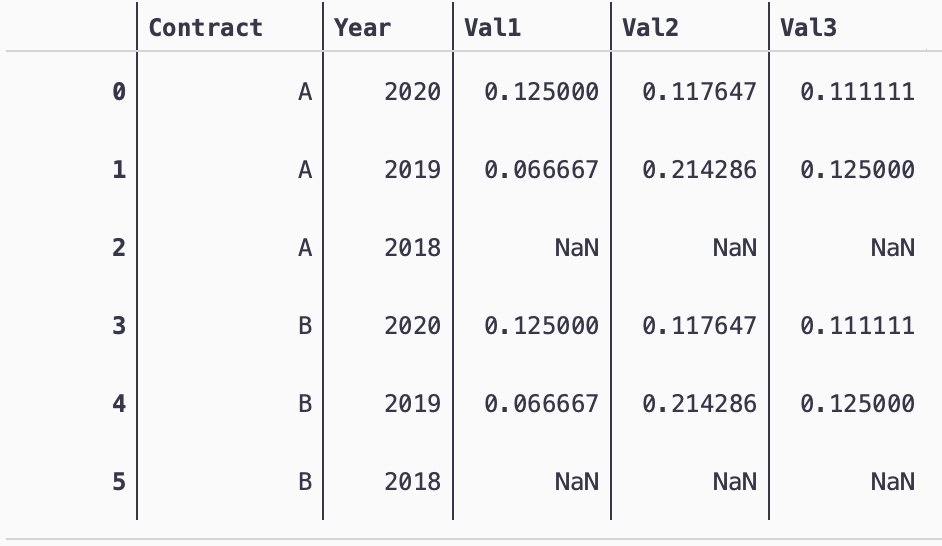
I wanted to find row wise running difference for Val1,Val2,Val3 after grouping the data on contract and sorting the data on contract and year so that the output looks something like:
Output:
| Contract| Year | Val1 | Val2 | Val3 |
| A | 2020 | (10/80)|(10/95)|(10/90)|
| A | 2019 |(5/75) |(15/70)|(10/80)|
|A |2018 |NaN | NaN | NaN |
| B |2020 |(10/80) |(10/85)| (10/90|
| B |2019 |(5/75) |(15/70)|(10/80)|
|B | 2018 | NaN | NaN | NaN |
I tried doing this using the sort groupby and diff in Pandas but i'm not getting the right output:
Code i tried:
df.loc[:, "Val1":"Val3"] = (df.groupby(df["Contract"]).diff().mul(-1).shift(-1)/
df.groupby(df["Contract"]).shift(-1))
This doesn't include Contract and year in the output. Where i'm going wrong?
CodePudding user response:
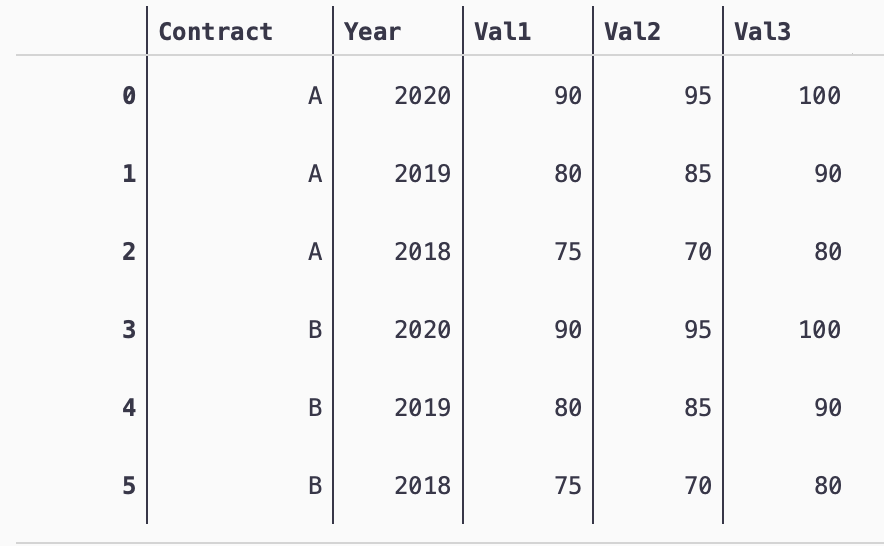
import pandas as pd
df = pd.DataFrame({
"Contract":["A","A","A","B","B","B"],
"Year":[2020,2019,2018,2020,2019,2018],
"Val1":[90,80,75,90,80,75],
"Val2":[95,85,70,95,85,70],
"Val3":[100,90,80,100,90,80]
})
df
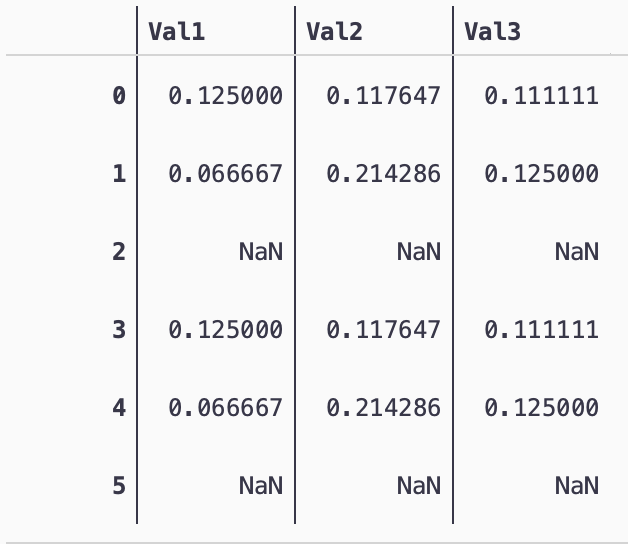
 Assume:
Assume:
Yearis in Descending order
Pandas has built-in function called pct_change
df2 = df.groupby(['Contract'])[['Val1','Val2','Val3']].pct_change(periods=-1)
df2
If you wanna assign the result back to df and overwrite the original values of Val1, Val2, Val3
df[['Val1','Val2','Val3']] = df2
df