I am quite new to python and tried scraping some websites. A few of em worked well but i now stumbled upon one that is giving me a hard time. the url im using is: 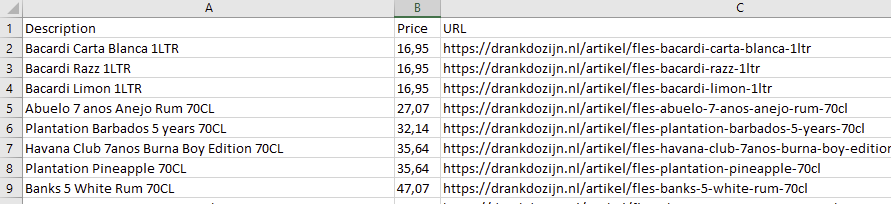
I recommend you print(data) to have a look at all of the information that is available.
The URL was found using the browser's network tools to watch the request it made whilst loading the page. An alternative approach would be to use something like Selenium to fully render the HTML, but this will be slower and more resource intensive.
openpyxl is used to create an output spreadsheet. You could modify the column width's and appearance if needed for the Excel output.