I am trying to find the first date of each category then subtract 5 days AND I want to keep the days inbetween! this is where I am struggling. I tried seq() but it gave me an error, so I'm not sure if this is the right way to do it.
I am able to get 5 days prior to my start date for each category, but I can't figure out how to get 0, 1, 2, 3, 4 AND 5 days prior to my start date!
The error I got is this (for the commented out part of the code): Error in seq.default(., as.Date(first_day), by = "day", length.out = 5) : 'from' must be of length 1
Any help would be greatly appreciated!
library ("lubridate")
library("dplyr")
library("tidyr")
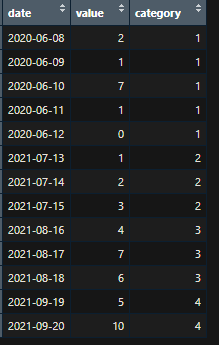
data <- data.frame(date = c("2020-06-08",
"2020-06-09",
"2020-06-10",
"2020-06-11",
"2020-06-12",
"2021-07-13",
"2021-07-14",
"2021-07-15",
"2021-08-16",
"2021-08-17",
"2021-08-18",
"2021-09-19",
"2021-09-20"),
value = c(2,1,7,1,0,1,2,3,4,7,6,5,10),
category = c(1,1,1,1,1,2,2,2,3,3,3,4,4))
data$date <- as.Date(data$date)
View(data)
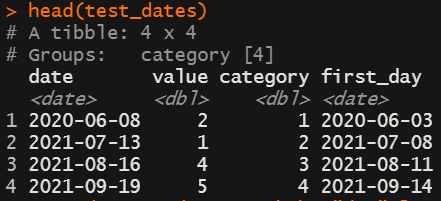
test_dates <- data %>%
group_by(category) %>%
arrange(date) %>%
slice(1L) %>% #takes first date
mutate(first_day = as.Date(date) - 5)#%>%
#seq(as.Date(first_day),by="day",length.out=5)
#error for seq(): Error in seq.default(., as.Date(first_day), by = "day", length.out = 5) : 'from' must be of length 1
head(test_dates)
CodePudding user response:
Here's one approach but kinda clunky:
bind_rows(
data,
data %>%
group_by(category) %>%
slice_min(date) %>%
uncount(6, .id = "id") %>%
mutate(date = date - id 1) %>%
select(-id)) %>%
arrange(category, date)
CodePudding user response:
@Jon Srpings answer fired this alternative approach:
Here we first get the first days - 5 as already presented in the question. Then we use bind_rows as Jon Srping does in his answer. Next step is to identify the original first dates within the dates column (we use !duplicated within filter). Last main step is to use coalesce:
library(lubridate)
library(dplyr)
data %>%
group_by(category) %>%
mutate(x = min(ymd(date))-5) %>%
slice(1) %>%
bind_rows(data) %>%
mutate(date = ymd(date)) %>%
filter(!duplicated(date)) %>%
mutate(x = coalesce(x, date)) %>%
arrange(category) %>%
select(date = x, value)
category date value
<dbl> <date> <dbl>
1 1 2020-06-03 2
2 1 2020-06-09 1
3 1 2020-06-10 7
4 1 2020-06-11 1
5 1 2020-06-12 0
6 2 2021-07-08 1
7 2 2021-07-14 2
8 2 2021-07-15 3
9 3 2021-08-11 4
10 3 2021-08-17 7
11 3 2021-08-18 6
12 4 2021-09-14 5
13 4 2021-09-20 10