I have 2 tables in MS SQL Server 2019 - test1 and test2. Below are the table creation and insert statements for the 2 tables :
create table test2 (id nvarchar(10) , code nvarchar(5) , all_names nvarchar(80))
create table test3 (code nvarchar(5), name1 nvarchar(18) )
insert into test2 values ('A01', '50493', '12A2S0403-Buffalo;13A1T0101-Boston;13A2C0304-Miami')
insert into test2 values ('A02', '31278', '12A1S0205-Detroit')
insert into test2 values ('A03', '49218', '12A2S0403-Buffalo;12A1M0208-Manhattan')
insert into test3 values ('50493', 'T0101-Boston')
insert into test3 values ('49218', 'S0403-Buffalo')
insert into test3 values ('31278', 'S0205-Detroit')
I can join the 2 tables on the code column. Task is to find difference of test2.all_names and test3.name1. For example 'A01' should display the result as '12A2S0403-Buffalo;13A2C0304-Miami'. A02 should not come as output.
The output should be :
Id | Diff_of_name
----------------------------------------
A01 | 12A2S0403-Buffalo;13A2C0304-Miami
A03 | 12A1M0208-Manhattan
CodePudding user response:
Here's one possible solution, first using openjson to split your source string into rows, then using exists to check for matching values in table test3 and finally string_agg to provide the final result:
select Id, String_Agg(j.[value], ';') within group (order by j.seq) Diff_Of_Name
from test2 t2
cross apply (
select j.[value], Convert(tinyint,j.[key]) Seq
from OpenJson(Concat('["',replace(all_names,';', '","'),'"]')) j
where not exists (
select * from test3 t3
where t3.code = t2.code and j.[value] like Concat('%',t3.name1,'%')
)
)j
group by t2.Id;
Demo 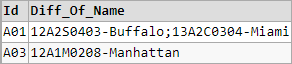
CodePudding user response:
I don't like the need to normalize. However, if one must normalize, STRING_SPLIT is handy. When done with the real work, STRING_AGG can de-normalize the data.
WITH normalized as ( -- normalize all_names in test2 to column name1
SELECT t2.id, t2.code, t2.all_names, n.value as [name1]
FROM test2 t2
OUTER APPLY STRING_SPLIT(t2.all_names, ';') n
) select * from normalized;
WITH normalized as ( -- normalize all_names in test2 to column name1
SELECT t2.id, t2.code, t2.all_names, n.value as [name1]
FROM test2 t2
OUTER APPLY STRING_SPLIT(t2.all_names, ';') n
), differenced as ( -- exclude name1 values listed in test3, ignoring leading characters
SELECT n.*
FROM normalized n
WHERE NOT EXISTS(SELECT * FROM test3 t3 WHERE t3.code = n.code AND n.name1 LIKE '%' t3.name1)
) -- denormalize
SELECT id, STRING_AGG(name1, ';') as [Diff_of_name]
FROM differenced
group by id
order by id
id Diff_of_name
---------- ---------------------------------
A01 12A2S0403-Buffalo;13A2C0304-Miami
A03 12A1M0208-Manhattan